This is the first in a series of posts about engineering at Mapzen – learn more here.
Operationally, Mapzen Search is comprised at a very basic level of an API and an ElasticSearch cluster. Where things get complicated is in the building of a pipeline that keeps the data in that cluster both up to date and highly available.
Overview
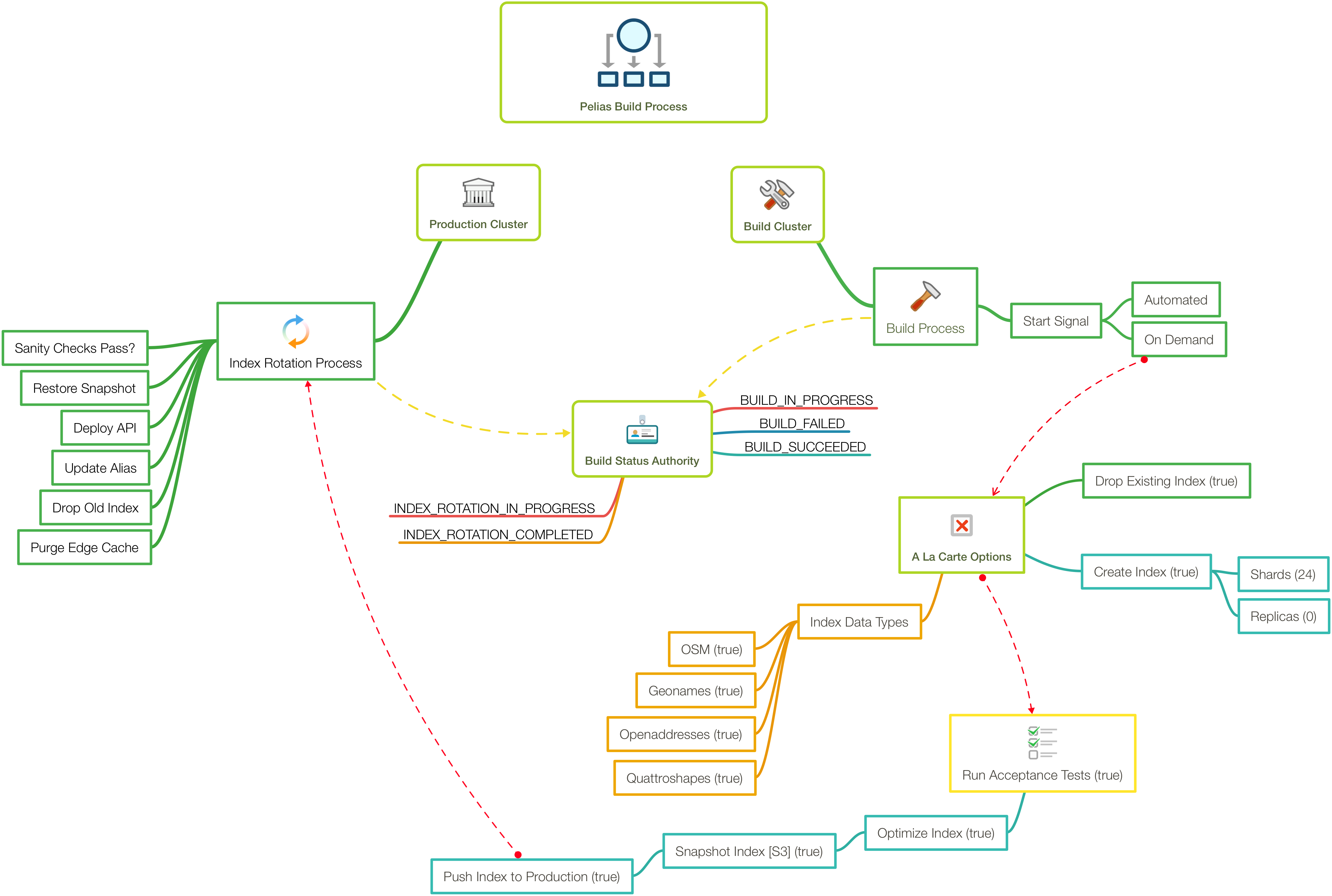
The build pipeline in all its glory (actually, somewhat simplified for easier viewing)
Arriving at the solution you see outlined above has been an iterative process. When we started working on Search over two years ago, simply indexing all of OSM took around 30 days. That made building any sort of automated build pipeline difficult, and in any event wasn’t on the immediate to-do list. Now, we index geonames, quattroshapes, osm and openaddresses in a little under two days. As the product has matured, so has the automation.
How Does It Work?
Underlying Services
Search is hosted in AWS, and we leverage a service called Opsworks. Every week, an automated process initiates a call to the API underlying that service, which kicks off a build. That build is run on a dedicated environment comprised of an Elastic cluster, the Pelias API and a Dashboard.
Import Performance
The dashboard is simply a nice way for us to visually watch the build process and to share that status with users. The process itself, which is crafted in chef, makes use of GNU Parallel to run several imports in tandem. This speeds things along substantially, as opposed to running each import serially. How many imports you can run in parallel will depend to a large extent on the hardware you’re using, both for the Elastic cluster and for the system on which the import process itself is running. We recommend using SSD volumes for both the data you’re importing (for example, an OSM pbf file), as well as for the leveldb volume for the Address Deduplicator if you’re doing (you guessed it) address deduplication as part of your import.
Testing & Backup
When the import completes, provided all the jobs ran successfully, we move on to acceptance testing. This is a crucial step in validating the data we just indexed as fit to move to production or not. Provided these tests pass and no regressions are detected, the index is optimized (critical for good performance!) and then a snapshot is taken. The snapshot is stored on S3 to allow us to easily retrieve old snapshots for testing, backup, etc., as well as to allow easy access from multiple environments where we might want to make use of it (e.g. production).
Roll to Prod
In the event there was a failure upstream, we notify interested parties and we can investigate the failure. Otherwise, at this point, the build itself is complete! Now we can move on to getting that index into production. Again, this is accomplished by leveraging the underlying Opsworks API. A request is made that results in a chef recipe being run against the production Elastic cluster. The recipe, in this case, executes some rather lengthy code I won’t bore you with. But in essence it does the following:
- checks for the availability of a new snapshot
- if available, performs a number of sanity checks on our cluster and the snapshot to ensure we can safely proceed
- loads the snapshot into the cluster
- updates the index alias to reference the new index
- drops the old index
- issues a purge request to the edge cache
Summary
And that, friends, is how we keep our Pelias data fresh and do so with a minimum of manual intervention. If you have questions about any of the specifics, get in touch!

{kind=link}