At the 2 year anniversary of the launch of Mapzen Search, the hosted instance of the open-source Pelias geocoder, we can’t help but reflect on the journey. Building an open-source product, that uses live open data and is also a live service with live users, can be challenging. It often feels like there is a never-ending chain of big and small decisions that build on each other. We thought it might be informative to share some of the choices we’re proud of and perhaps some that we’ve had to rework a few times. Get ready for a fast-paced tour through the evolution of an R&D open-source geocoder that became a commercial service, now handling millions of requests.
Let’s start with a little background on what the Mapzen Search team has built. We work on a geospatial search engine known as a geocoder. A geocoder is a magic tool that can translate textual addresses into lat/lon pairs and vice-versa. It also understands venues and names of cities, regions, and countries.

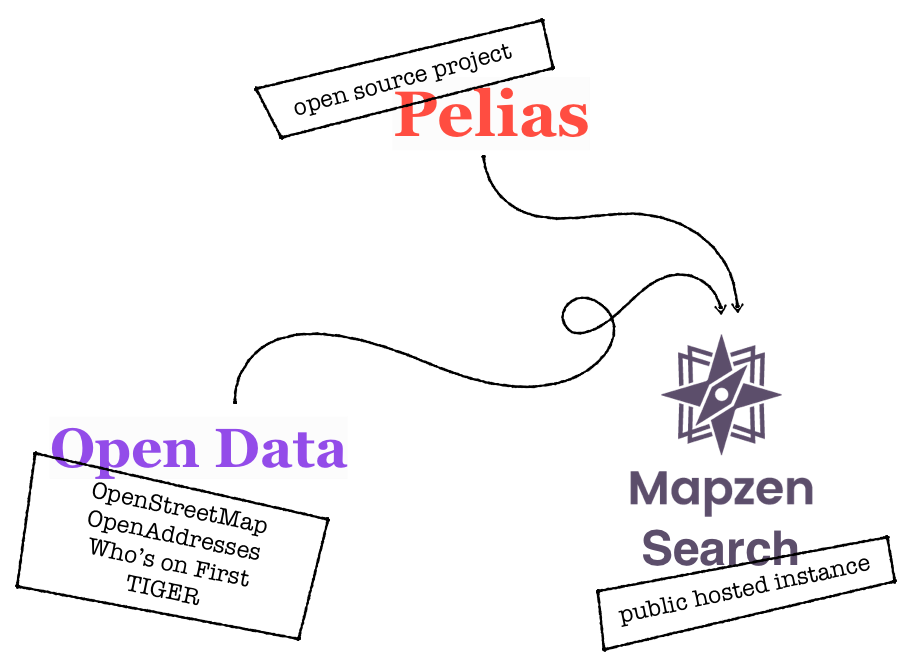
So we made one of these geocoders, and we are certainly not the first to do so. We named our geocoder Pelias… if you ever meet our founder Randy Meech, ask him why he did that 🤷. We built our geocoder in the form of an HTTP service, so that applications anywhere connected to the internet could ask the geocoder about their addresses and places. HTTP services are a very accessible framework and we wanted to be really accessible.
Now, while the Pelias service can run on any network and use any data fed into it, in order to make it truly accessible we decided to host a public instance of it with only open data sources and allow anyone to access it from their web applications or other connected software. We call our hosted instance Mapzen Search and we ask our users to sign up for an API key in order to protect the service from getting overloaded with incoming requests by using rate limiting.
On November 5th, 2013 Randy Meech committed the first version of the Pelias geocoder to github. It looked very different at the time, written in Ruby, and had just a fraction of the functionality of today’s engine. He also duly noted in the README that it was, in fact, experimental. It started as an R&D effort and we remain true to those roots today, with our excitement and willingness to innovate and continuously learn from our experimentation.
Later that year at the Code for America Summit, Randy unveiled the grand plan for Pelias and its core values.
Two years worth of hard work later, at the Code for America Summit of 2015, Mapzen announced the release of the Mapzen Search API, which is a publicly-available hosted instance of the Pelias geocoder.
The hosted service was officially launched on September 30th, 2015. We also tagged all the source-code with v1.0! At that point we felt that we reached a ceremonious end of our R&D journey. We accomplished the goal of a public geocoder, running on open data and available to all. Life was great! We even made beer mugs to celebrate.

But the work was just beginning. Now there were real live users on the other side of those incoming requests! Now we had promises to keep. Now we had to represent the open data we were using in its true light. This was a whole new category of challenges for our team.
There are many things we learned along the way but some areas stand out more vividly as we look back. Each shows a trajectory and a desire to continuously improve our practices as well our products.
Documentation
We were particularly proud of our Mapzen Search API documentation. It was (and is) conversational, approachable, yet informative. We had done a ton of work on it, with the steady hand of Rhonda Glennon leading the way, before the 1.0 launch, since prior to that the only documentation we had was a markdown file that was accessible via one of the API endpoints. We had made a huge leap forward from those days. We even get compliments on it occasionally. Life was great!
I’ve never seen an api with a methods param, this is amazing omg
— Allen Tan (@tealtan) April 24, 2017
Then after a few months of work on some new functionality and a few minor releases, we came to an embarrassing realization that we had not been keeping any release notes. Release notes are actually pretty important when working on an open source project! They let the world know what we’ve fixed or added in the software. For those using the open source project, it’s a tool for evaluating whether or not an update is necessary. For those using the hosted API, it’s a way to know why search results have changed and whether or not the client code needs to be updated in order to continue functioning correctly. So we quickly strapped those together for both the Pelias project and Mapzen Search API. Each requires a slightly different tone and level of detail. Pelias release notes need to include details about the changes made within the code, even when they are undetectable to the end-user. Mapzen Search release notes, however, have to denote updates to the builds and changes to the API protocol, such as new query parameters, for example. We made release notes a part of our workflow and life was good again!
Testing
If there is one thing our team wholeheartedly agrees on it’s testing! While the concept of testing software is not at all contentious, there are many ways to claim test coverage and our journey involved figuring out which strategies made us feel confident and covered.
About 2.5 years ago, long before the 1.0 release, the Pelias engine was covered with an impressive number of unit tests. Unit tests verify a single module or small slice of the codebase. These types of tests are allowed to be intimately familiar with the inner-workings of the code they are exercising. These tests are allowed to mock out all dependencies to ensure that only a single thing is being tested at a time. Unit tests are essential for complex parts of the codebase where it’s easy to make a mistake and assumptions about how the code should work need to be documented using nothing less than more code.
All of our unit tests are executed on a regular basis. We run them at every git commit, using pre-commit hooks. We run them using TravisCI anytime we push code to github. If any of the unit tests fail, the code changes cannot be accepted until all is fixed.
While unit tests are a great way to maintain individual parts of the code, they do very little to ensure that the overall system hasn’t been compromised. They don’t notify you when one module is not using another module correctly, or when the external data format has changed, thereby changing all the results. For that sort of verification, you need what’s known as acceptance and functional tests. These types of tests treat the product as a black-box, not making any assumptions about the internals of the system and exercising it as an end-user would.
Acceptance tests are a special type of functional tests that an engineer writes when embarking on a new feature. They set the requirements for that new feature and the work can only be claimed complete once those tests are passing. Functional tests are all the acceptance tests the team has accumulated over the life of the product as well as any new ones that get added when a bug is found and fixed.
Looking back to that distant time 2.5 years ago, the search team wasn’t using any functional testing strategies and was practicing what we came to call feels-driven development. Our functional testing strategy consisted of asking teammates to run their favorite queries manually and see if they felt the system was preforming better or worse. The only feelings this strategy ever resulted in were uncertainty and fear.
So we sat down and created a very simple framework for creating and running what would become our acceptance tests. This framework allowed us to specify input parameters, as users would when sending it queries, and then documenting an expected result. When the tests run, if the expected results don’t match actual ones, the system yells at us about regressions.
We also have tests marked as known failures, which are placeholders for future bug fixes. If the recent changes made those known failures pass, the system congratulates us on improvements. This revolutionized the way the team worked and almost immediately instilled a sense of order and peace of mind. We knew we weren’t going back on previously working functionality, and we could be confident that new features would be verified before ever making it to production. We really loooove <3 our acceptance test suite! It has helped us catch countless issues during development and staging, saving our users from having to experience them. We run these tests at every step along the development process and life is great, for the time being!
As we further improve our product and the work transitions from feature development to incremental quality and accuracy improvements, it will become increasingly difficult to capture the impact of many changes. This sort of trend analysis is much better done by machine than humans. We will need to rethink our current approach and supplement the existing strategies with new data-driven models. Data modeling, mining, and quantifying will be the building blocks with which we create this next generation of testing tools. Data-driven development will soon be the only reasonable way to account for a whole world of places. This approach will also help us identify gaps in quality using statistics instead of relying on manual bug reporting. #gloriousfuture
Data Imports and Build
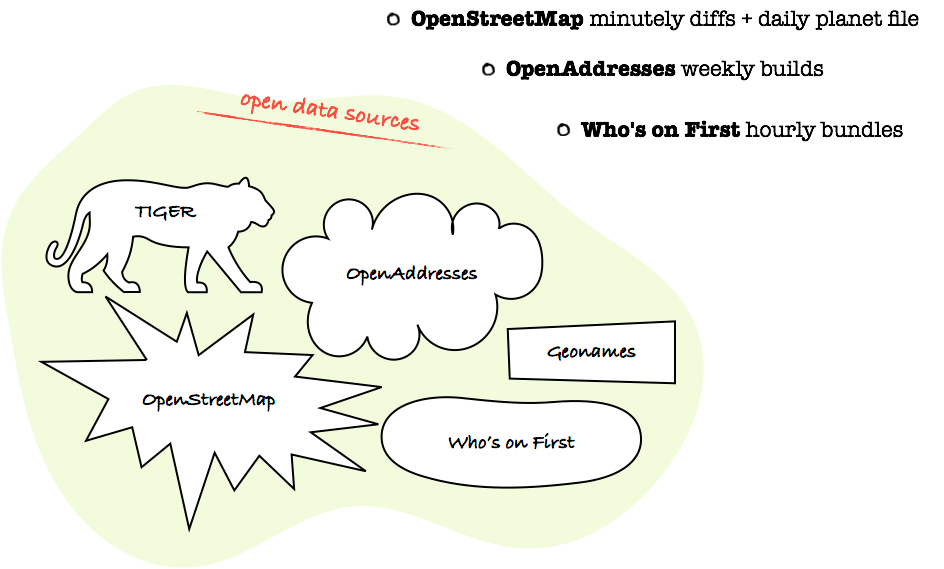
The hosted Mapzen Search API builds and serves only open geospatial data. At this time that data comes from four different and independent sources: OpenStreetMap, OpenAddresses, Who’s on First, Geonames, and TIGER. Each of these sources is updated at different intervals and each publishes the updates in their own way. OpenStreetMap, for example, has minutely diffs and regularly updated planet files. OpenAddresses does a weekly build. Who’s on First has just updated their infrastructure to build the world bundles hourly.
When we talk about importing and building these various datasets into a single database, we’re talking a LOT of data that needs preprocessing before it can be inserted into our backend data-stores. We are currently up to over 530M records just in our Elasticsearch index.
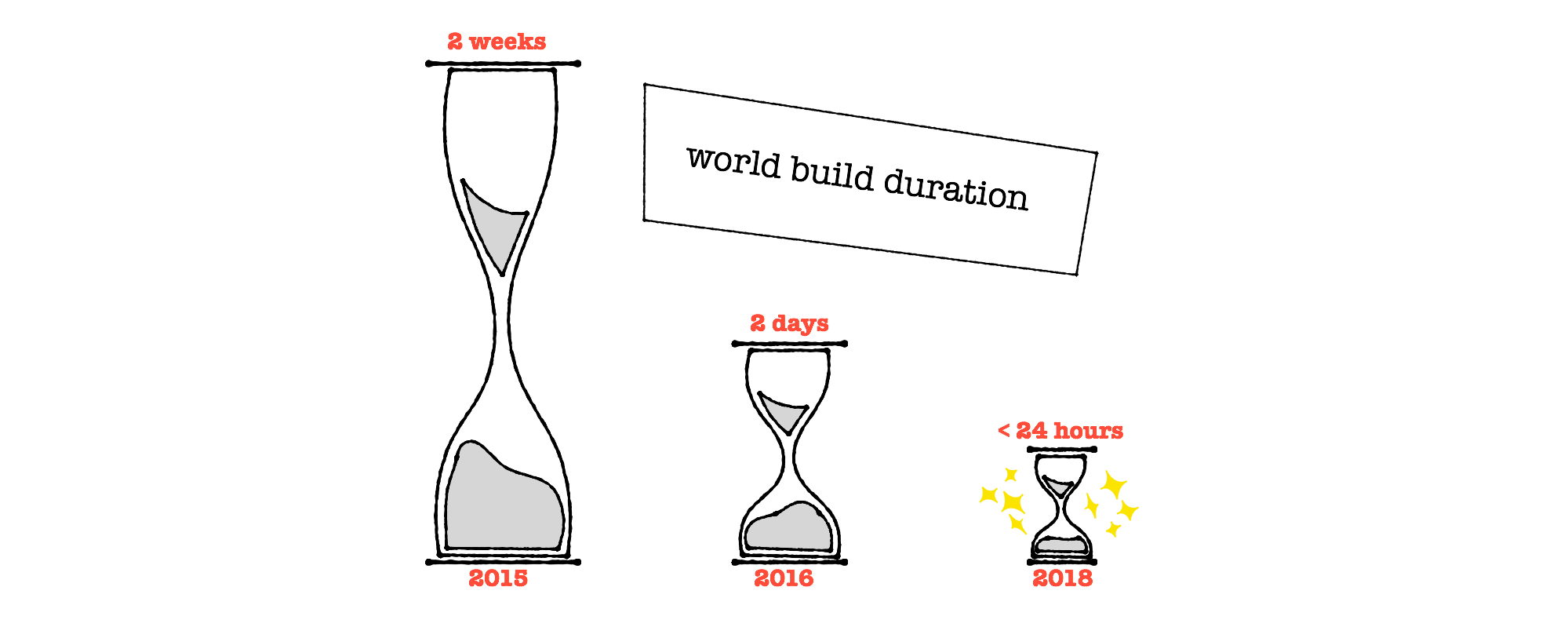
We do our best to represent all the data in its truest and freshest form, which currently means a weekly build across all datasets. Over 2.5 years ago, it was taking on the order of 2 weeks to build the data for the whole planet! That’s a long time to wait to see if our code changes broke everything or fixed it. 🤞
Six months later we focused on optimization and brought that down to just under 30 hours, where we remain today! Slow… clap… But we’re not done yet; we have set an internal goal to get to sub-24 hour builds by the end of this year, and we have every reason to believe that’s entirely within reach.
In the beginning of each build cycle, we download the most recent data directly from the source. We don’t always control the contents or availability of the data, and download errors or corrupt bundles can be a big bummer for our build process.
For example, if a server is down and we cannot download OSM or Geonames data during our build process, the build cannot go on as planned. Manual intervention is required to figure out what went wrong and the whole process stalls.
Furthermore, if a single source’s latest data download is unavailable for an extended period, the builds stop even if other sources are perfectly fine.
So we recently started a daily data download script that would collect and validate the data (as much as possible without a full build) from all sources. Builds then use the latest known good data when it comes time to build instead of downloading it directly from the source each time. This is an improvement, but we want to go further!
Our plan in the next year is to generate containers that have all the data inside them and can be mounted onto or referenced from any of our service machines, thereby creating what we’ve been referring to as data-source-packs (the name will catch on eventually). The containers will be generated daily and we’ll store some reasonable number of recent images in case the latest is causing trouble. This will also allow us to build different databases for each of our underlying parts of the engine using the same exact version of the source data. Without this important step, there is no guarantee that the data didn’t change between the start times of each build process.

Microservices
Back in 2015, the Pelias API was a pretty classic monolithic codebase. All the functionality that the API required was implemented directly in the API module. The only external utility the API was accessing was the Elasticsearch datastore. Of course it was only a matter of time before the API became too large to maintain effectively. It also started requiring more memory per instance to support all the new and improved functionality. With the introduction of the libpostal address parsing utility the memory requirements became significantly higher per API machine. Then we brought all the admin geometries into the API in order to perform faster and more accurate point-in-polygon computations for our reverse geocoding functionality. That came with hefty memory requirements as well. It soon became obvious that we needed to systematically move those parts of the system into separate services.
With this distributed system come many benefits. Each service can be tested thoroughly without the blanket of the full API obscuring it. Each service can be deployed behind a load-balancer and only requires enough instances to support demand for that specific feature. In a monolithic system, in order to support more general requests we’d need to spin up more large machines that were idle a majority of the time. We also benefit from faster startup times for most services since they are only responsible for loading a small fraction of resources.
There was a recent revelation from one of our teammates that due to the way we had broken up the functionality of the API there was no longer a single point of failure and a good portion of the system now continues to work even when one of the major components is missing.

Nowadays, when new features emerge they are usually developed as independent services and then integrated into the API using a lightweight service wrapper pattern. We love microservices!
While things aren’t perfect and there are still many challenges to look forward to, life is pretty great! It’s even more great when we consider how far we have come in just a couple of years time. We are proud of the work we are doing and hope to continue serving our users and the open-source community in a reliable and transparent way. Thank you for being part of our journey!

){kind=link}