This summer, Mapzen embarked on a large project to quantify and visualize name translation coverage in Who’s On First, and to add new translations from GeoNames by walking the concordance between the two datasets. Much of the work was done by Nathaniel Douglass, our summer intern on the Data team.
Who’s On First is Mapzen’s big list of places, each with a stable identifier and descriptive properties. These places represent various placetypes like country, region, locality, and even marinearea.
In addition to having every place documented, an overarching goal for Who’s On First is to catalogue all names in all the languages.
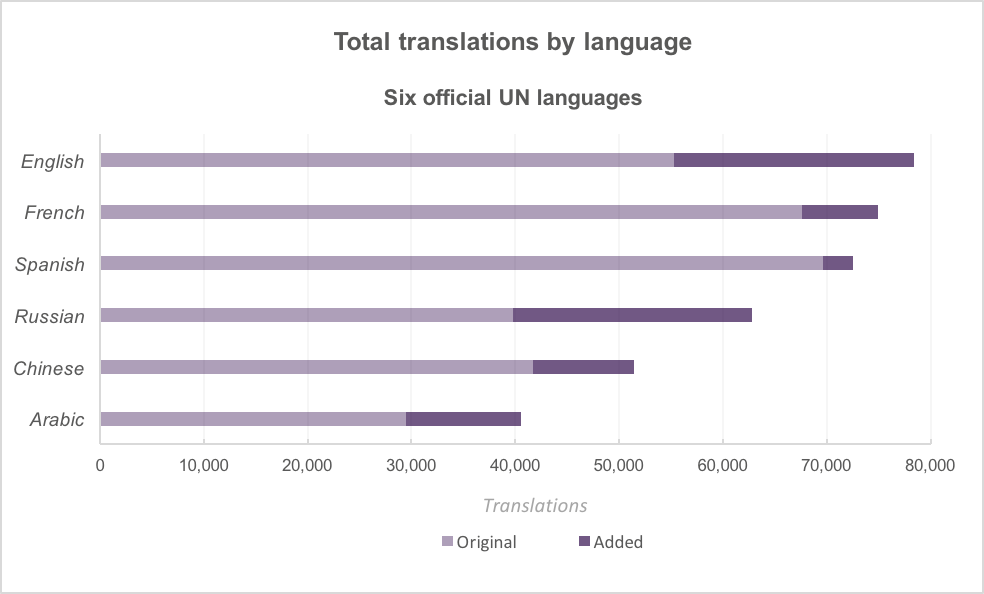
Above: The number of new translations added this summer, for the six major world languages used by the United Nations. For example, English gained 23,115 new name translations, while Spanish gained 2,916 new name translations.
Previous work around names…
Last summer, Olga wrote about adding name translations from Wikidata to Who’s On First. That Wikidata effort add nearly two million localized names for over 135,000 Who’s On First records, joining earlier names from Geoplanet. Nathaniel Douglass has continued that work this summer. Now over to him!
Tackling the issues
Our goal, and specifically, my internship task, was to add more of these name labels for more places. But there are so many names!
Not only do I want to ensure that Who’s On First has new and accurate name: properties, but I also needed to ensure the following is true for Who’s On First records:
- The
name:properties are using correct ISO language codes. - The
name:eng_x_preferredproperty is present if the record has an existing Englishwof:name. - Concordance values for GeoNames are set, which can yield new
name:properties.
Where is my starting point?
It’s safe to say that adding all missing names is much too large of a task for one humble intern to accomplish within two and a half months. So, I needed to ask myself one question:
“Where do I start?”
Before running name import scripts and importing new data, it was important for me to visualize the amount of names present. I did this by programmatically creating charts using Python and Excel.
The nitty gritty…
The International Organization for Standardization (ISO) maintains standardized language codes called the “ISO 639 Standard”. The ISO 639-2 language codes are used for the principal language identifier in Who’s On First’s name: properties (for more information on our use of ISO language codes and RFC 5646. See our properties and names repositories), for example:
"name:eng_x_preferred:[
"North America"
],
"name:lat_x_preferred:[
"America Septentrionalis"
],
"name:sin_x_preferred:[
"උතුරු ඇමෙරිකාව"
],
"name:spa_x_preferred:[
"América del Norte"
],
The above name: properties show “North America” in English, as well as the Latin, Sinhalese (Sinhala), and Spanish translations.
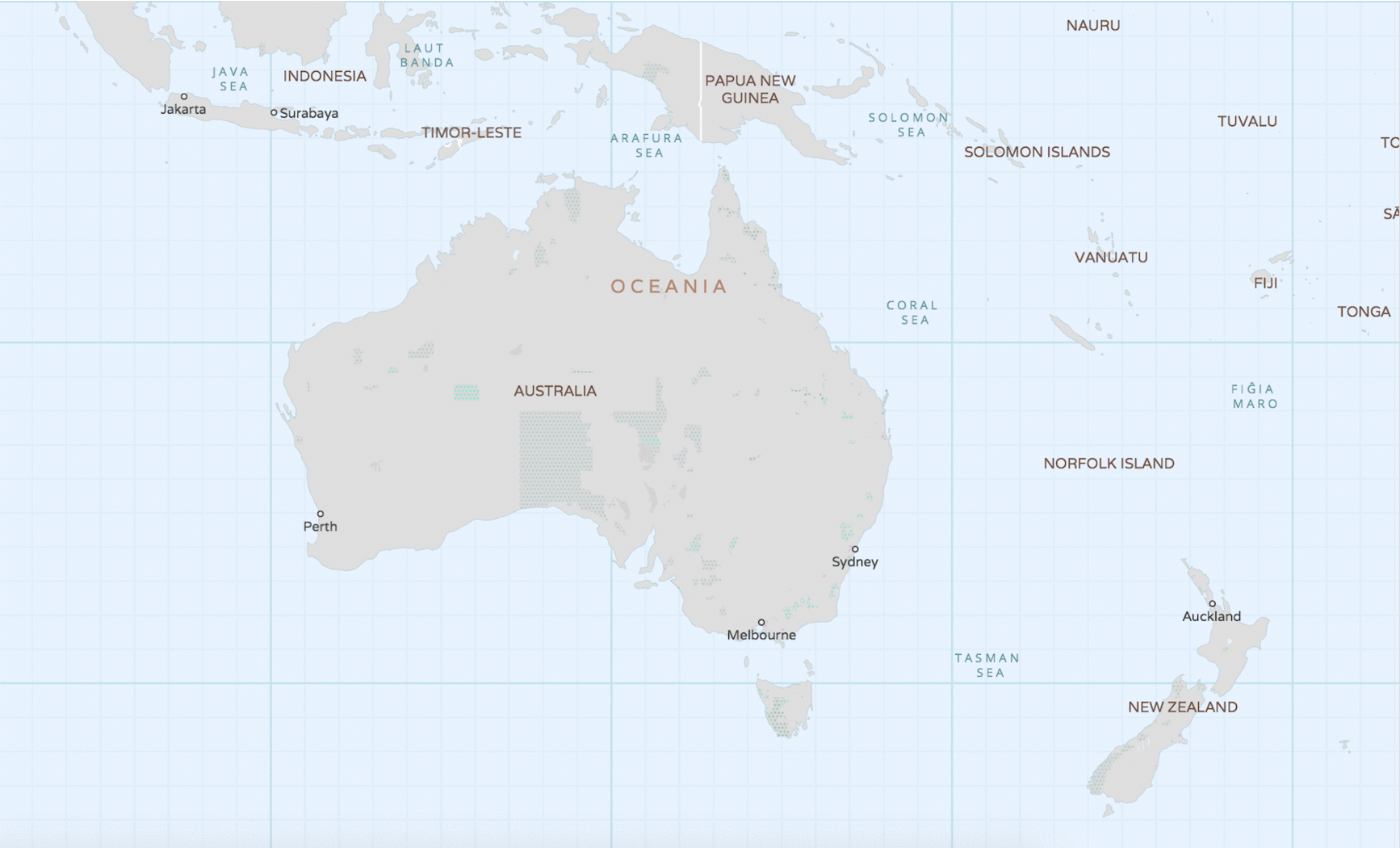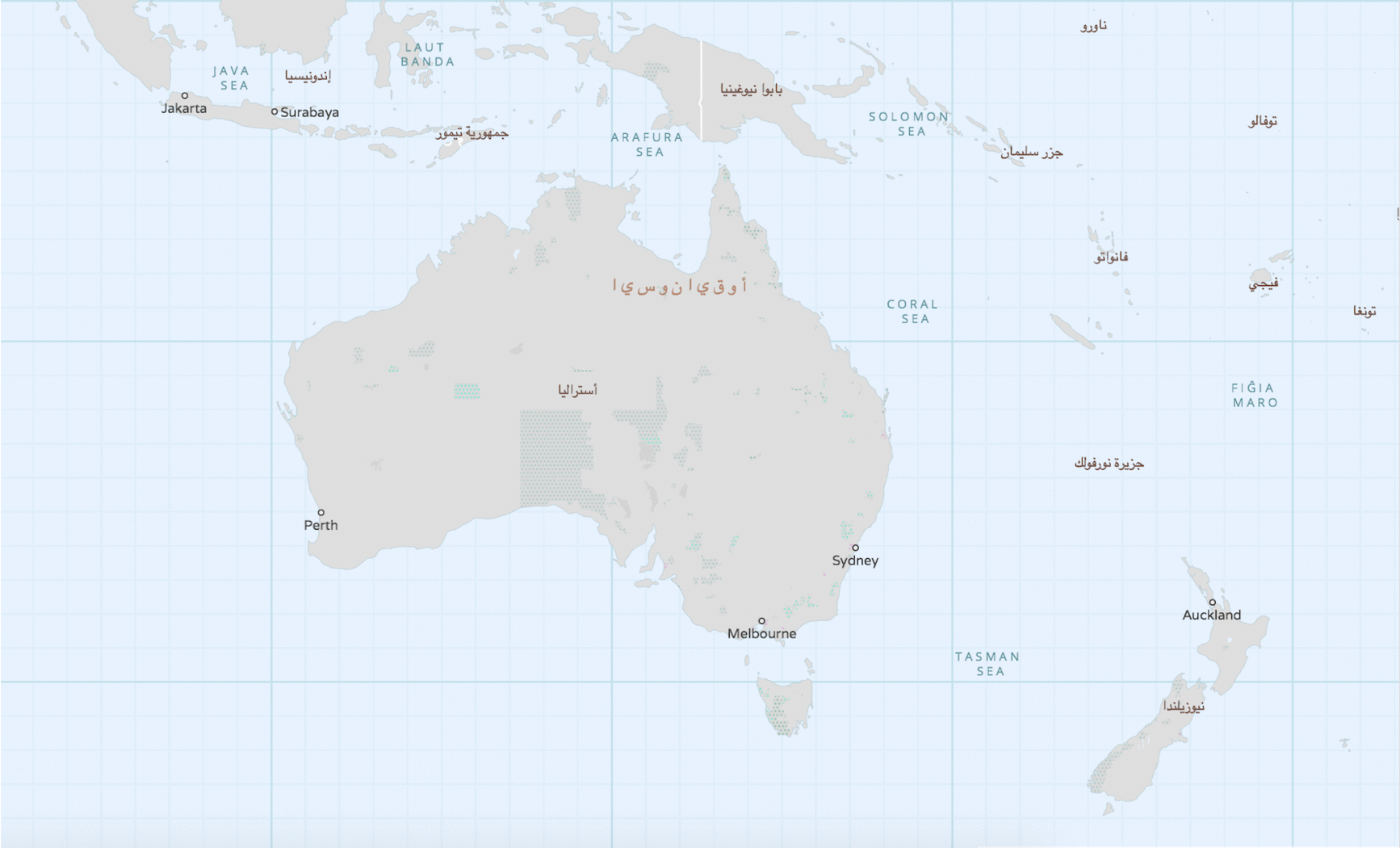
Above, the continent of Australia, is shown in Mapzen’s Bubble Wrap basemap style. You’ll notice the Australia label is set to the default language (in this case, English), and, when we switch the name label to Arabic, we see the label change to أستراليا. (You can do this in Bubble Wrap by toggling the “language” drop-down in the Controls menu, or by defining the `uxlanguage` global in Tangram)_.
Less is more (at least when it comes to names)
While ISO 639-2 catalogues over 450 language codes, I am mostly interested in the most-spoken languages of the world. Lucky for me, Tilezen (which powers Mapzen Vector Tiles) lists 20 common languages based on the six official languages of the United Nations, as well as the most commonly referenced languages on Wikipedia. A breakdown of those languages, below:
| Language (ISO-639-2) | |||
|---|---|---|---|
| Arabic (ara) | French (fra/fre) | Italian (ita) | Russian (rus) |
| Bengali (ben) | German (deu/ger) | Japanese (jpn) | Spanish (spa) |
| Chinese (zho/chi) | Greek (ell) | Korean (kor) | Swedish (swe) |
| Dutch (nld/deu) | Hindi (hin) | Polish (pol) | Turkish (tur) |
| English (eng) | Indonesian (ind) | Portuguese (por) | Vietnamese (vie) |
Who’s On First provides names in more than 60 languages, but not all languages have equal coverage. There are 10 languages with great coverage (more than 50,000 features translated), and another 25 language with good coverage (at least 10,000 features translated).
I want to ensure that the name translations are present in the above languages, but I also need to verify translations are available at different zoom levels in our map house styles. Zoom levels are present in Who’s On First records as the mz:min_zoom and mz:max_zoom properties and indicate when a label appears on a map. By querying records by their mz:min_zoom and mz:max zoom property values, I will get a more comprehensive understanding of our name translation coverage.
Less is more (at least when it comes to features)
When I was looking at online map providers and print atlases at the beginning of my internship, I noticed that it’s often just the low-zooms that are translated into all the languages, with native language names (and sometimes a romanized or “English” name) being dominant at mid- and high-zooms.
Natural Earth provides a curated list of a few thousand (instead of million!) important places tuned for low-zoom cartography. Using a pre-release version of the upcoming Natural Earth version 4 data (stored into mz:min_zoom, mz:max_zoom properties in Who’s On First), I was able quantify the entire gazetteer and a smaller set of features to focus on the features used to label maps at low-zooms.
Let’s dive into all that…
Grouping records
I crawled through the whosonfirst-data repository to gather statistics about each record for specific placetypes and zoom levels. I then grouped records into the following categories:
- By placetype
- By placetype, then by language
- By placetype, then by zoom
- By placetype, then by zoom, then by language
For this work, I focus only on the following placetypes: country, dependency, disputed, region, locality, continent, ocean, and marinearea - the features visible at low- and mid-zooms on a map and most useful for point-in-polygon lookups. Other placetypes like county, neighbourhood, and venue were left for another day.
After obtaining the wof:name, wof:placetype, mz:min_zoom, mz:max_zoom, and the existing name: properties, I flagged and grouped records by the categories above. The output was a series of csv files, which I crafted into visualizations.
Maps!
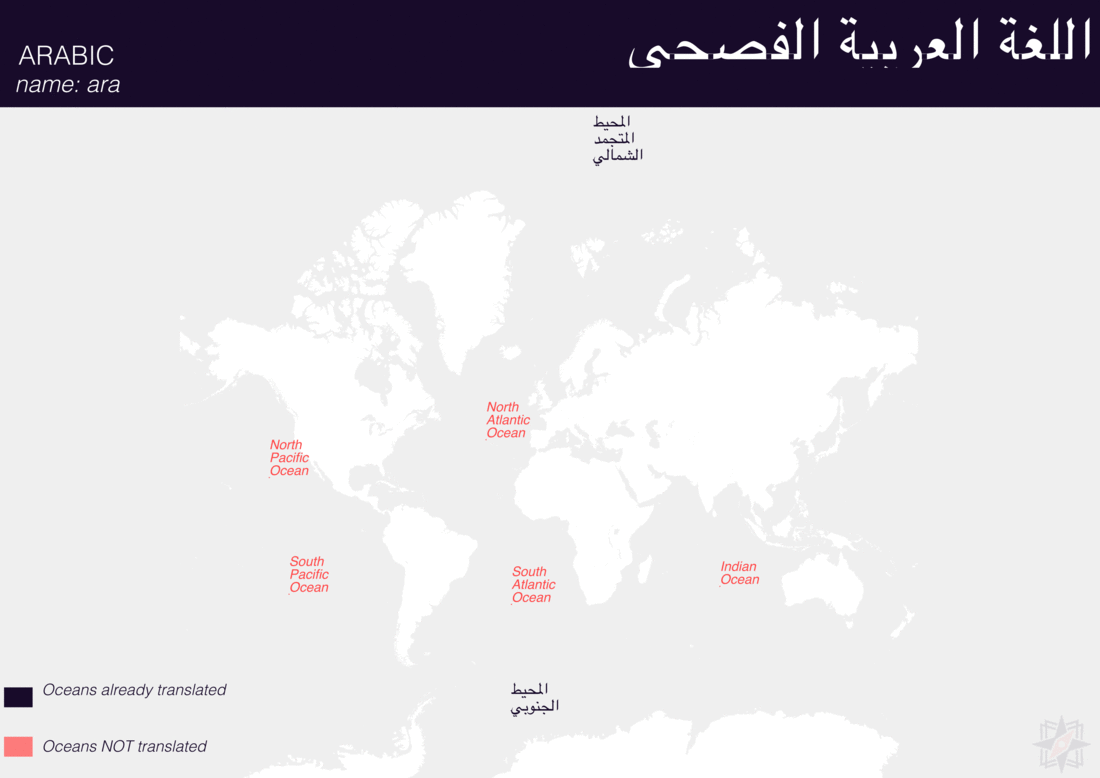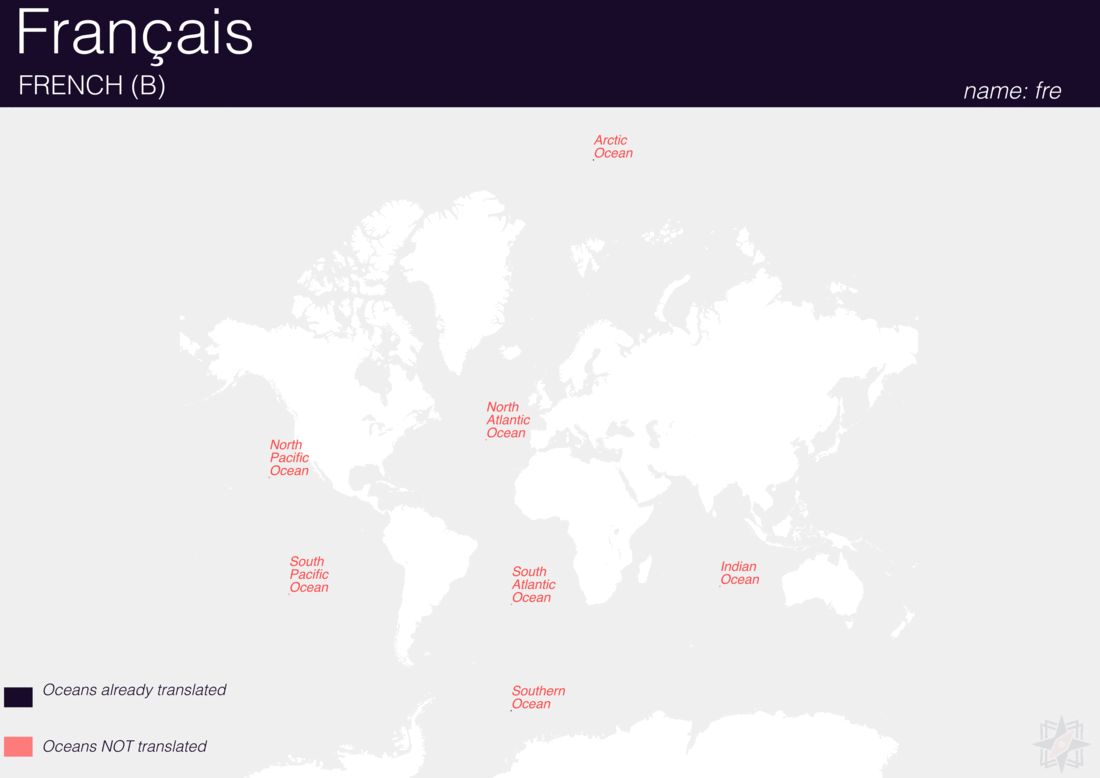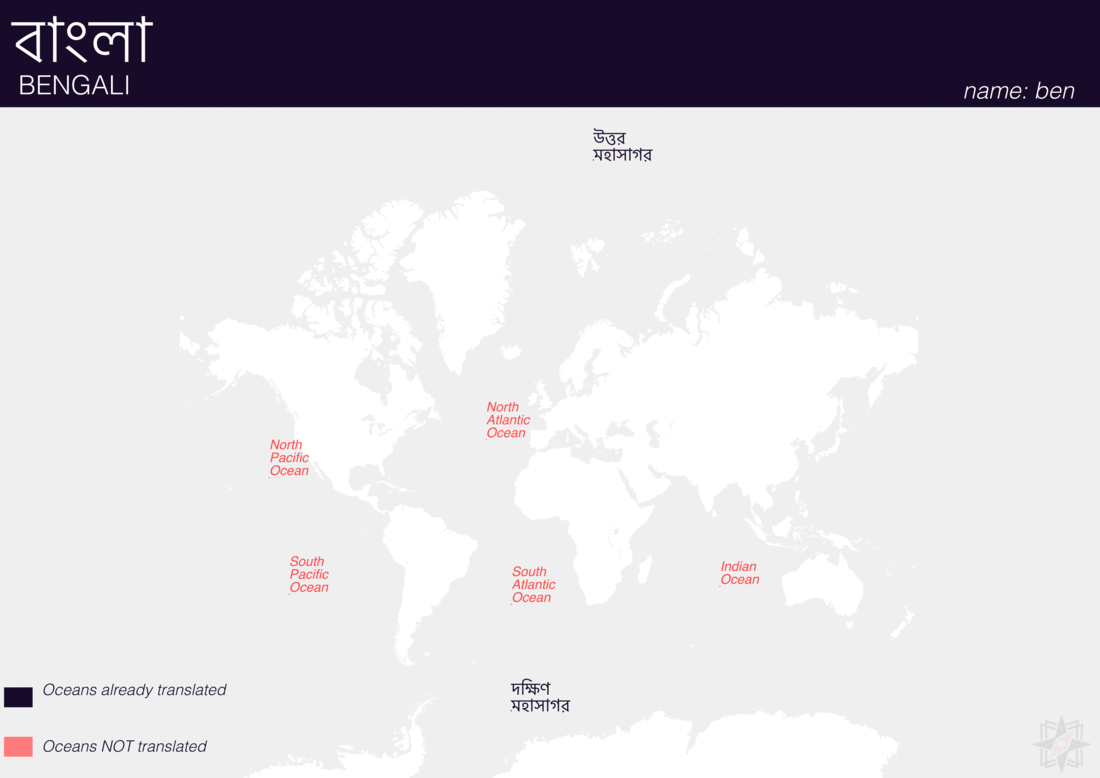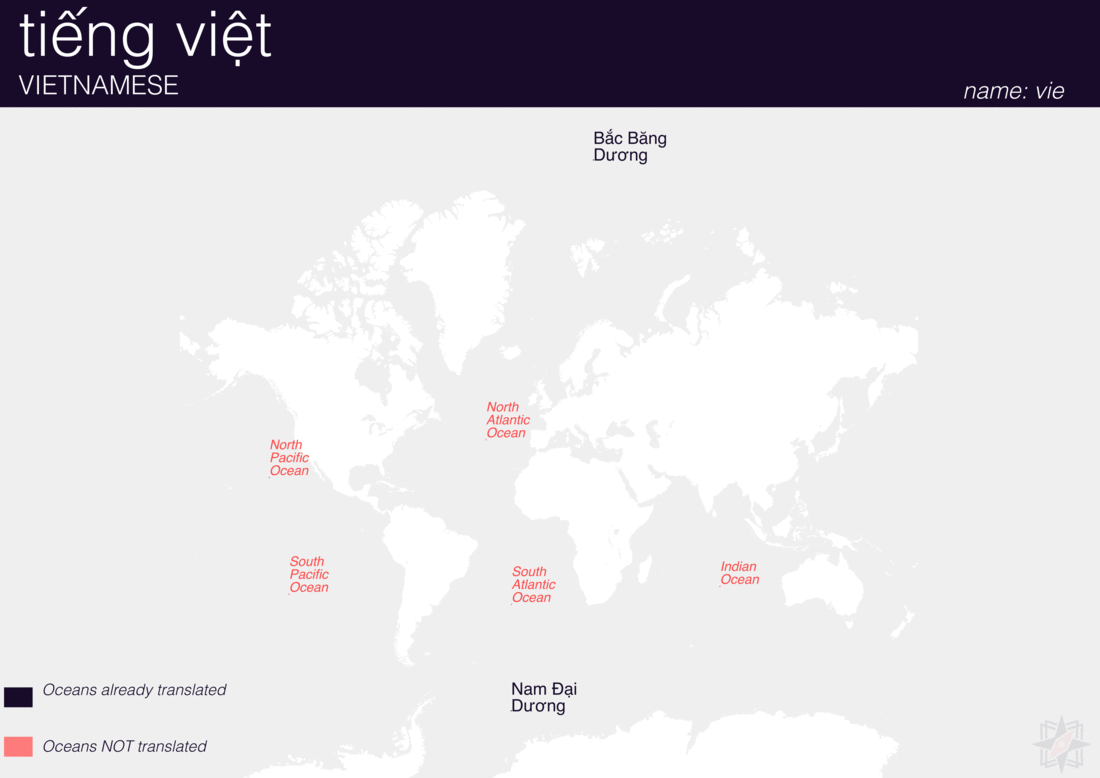
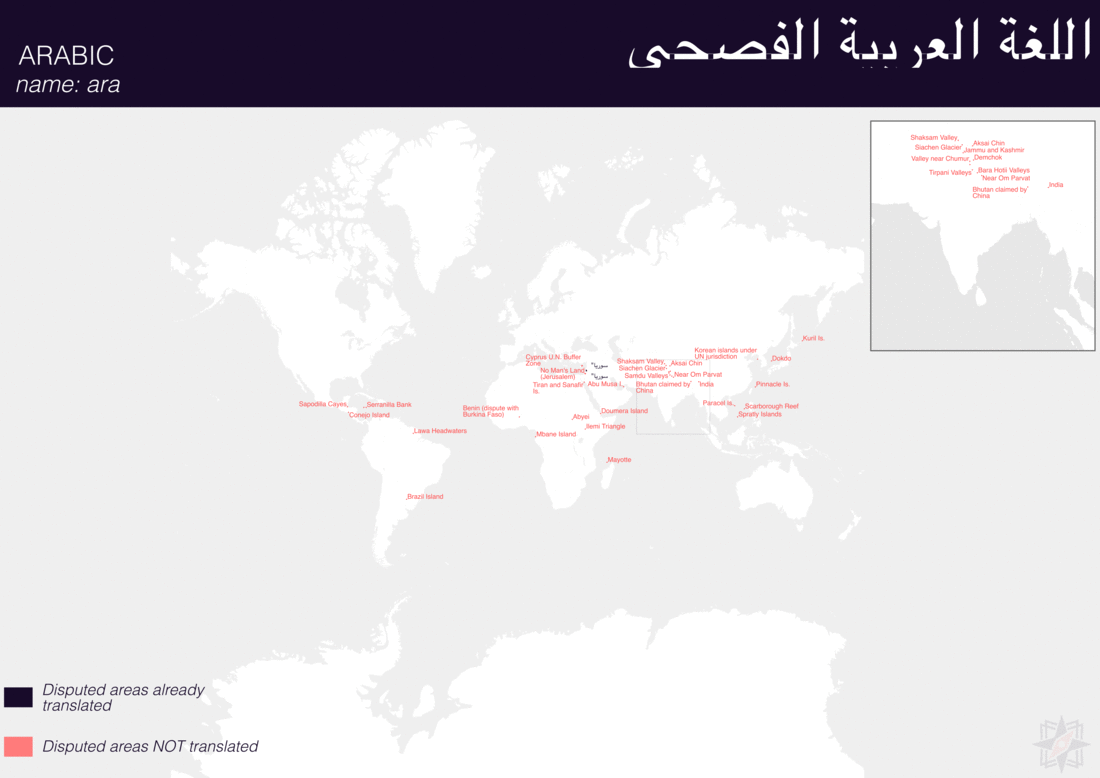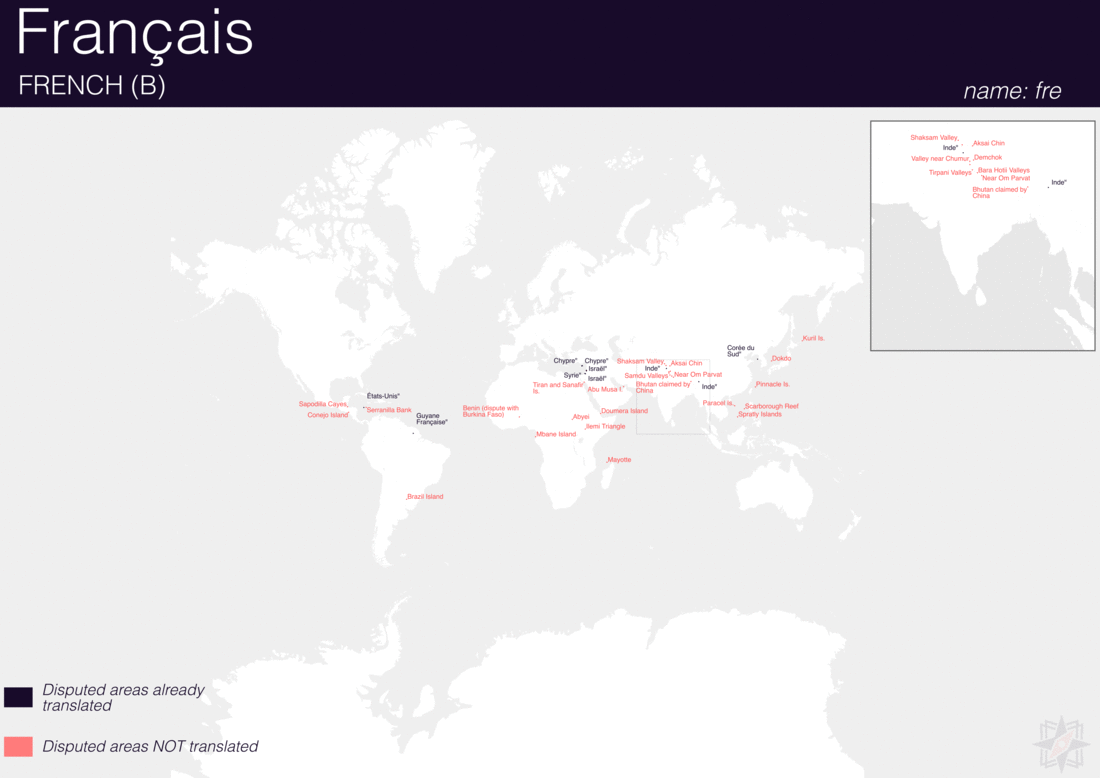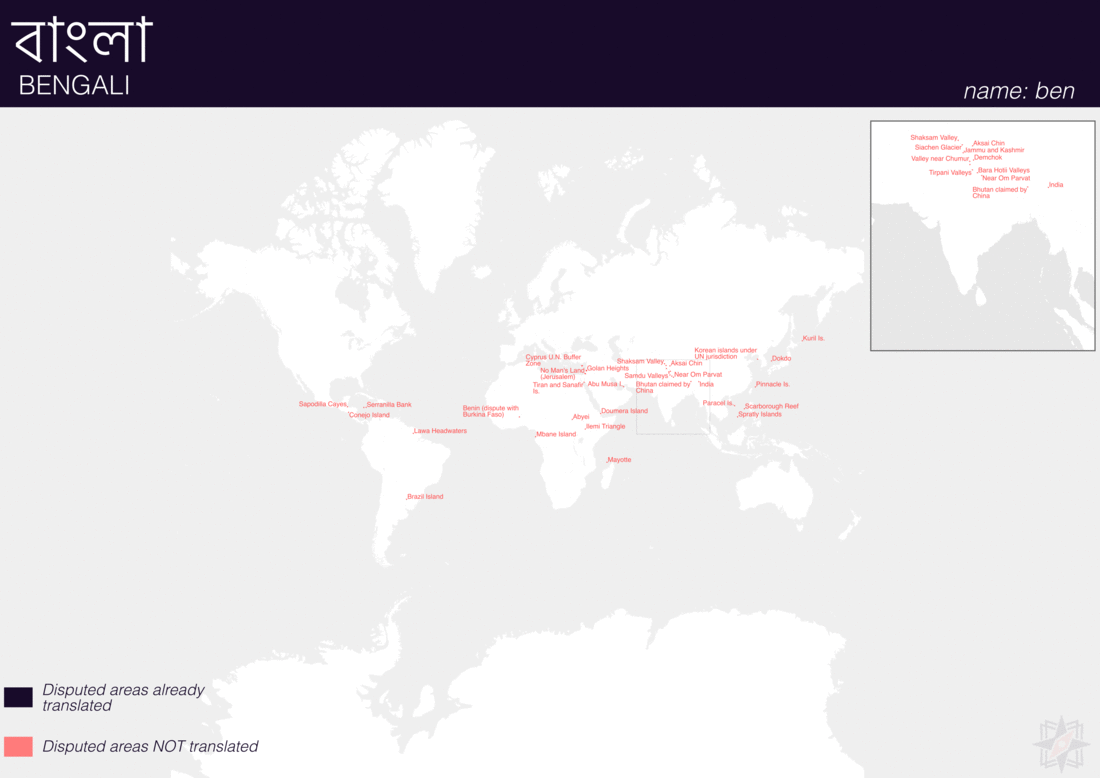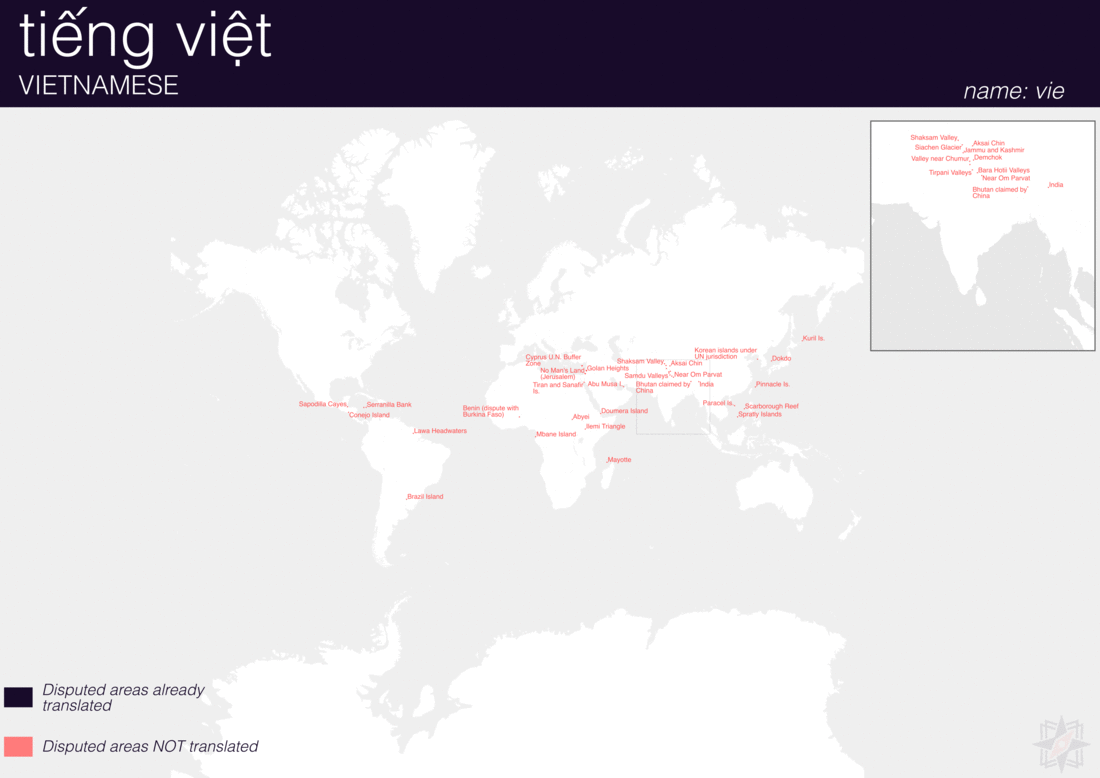
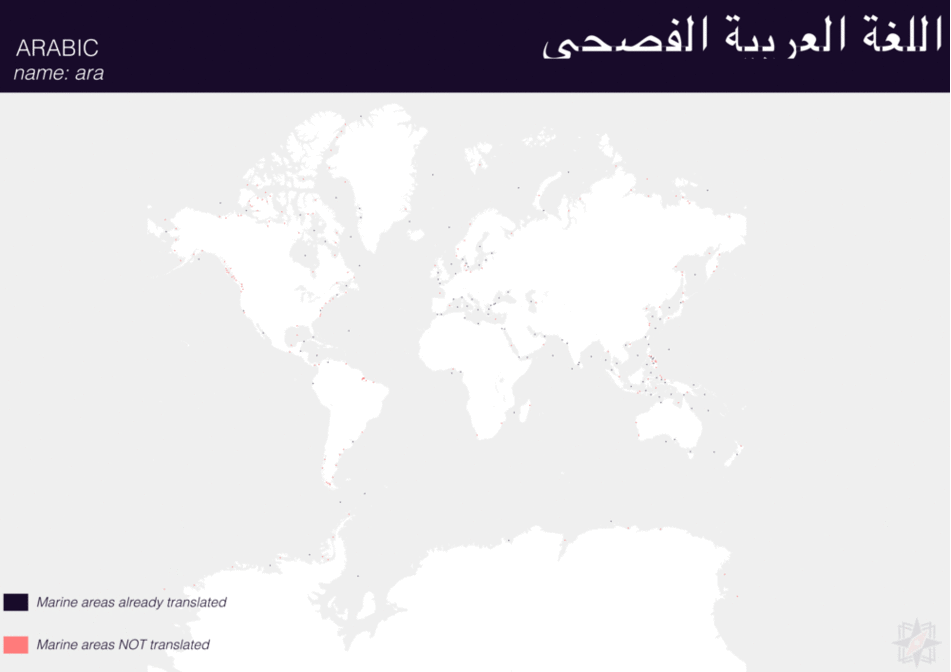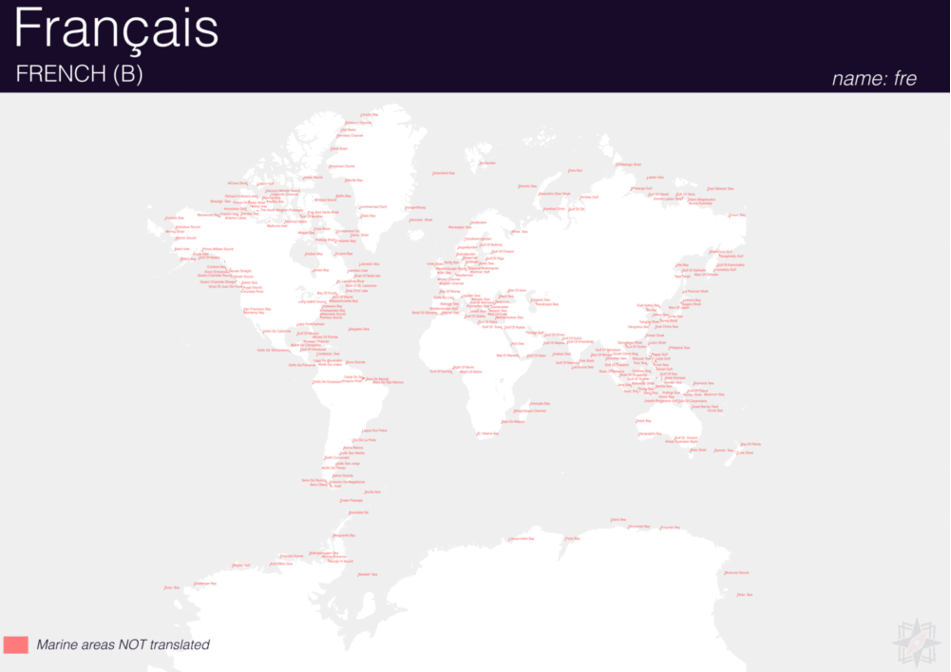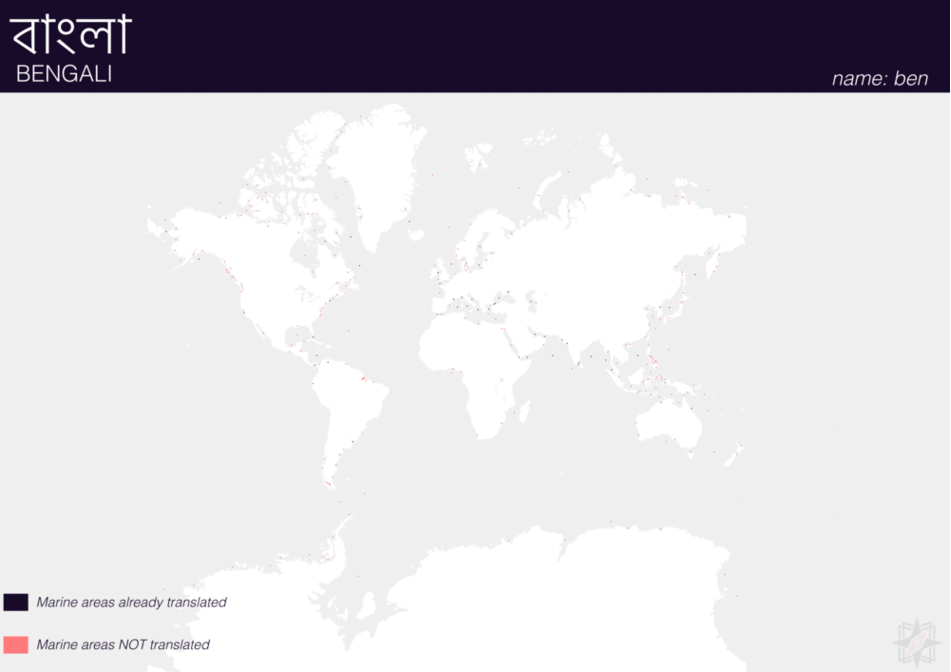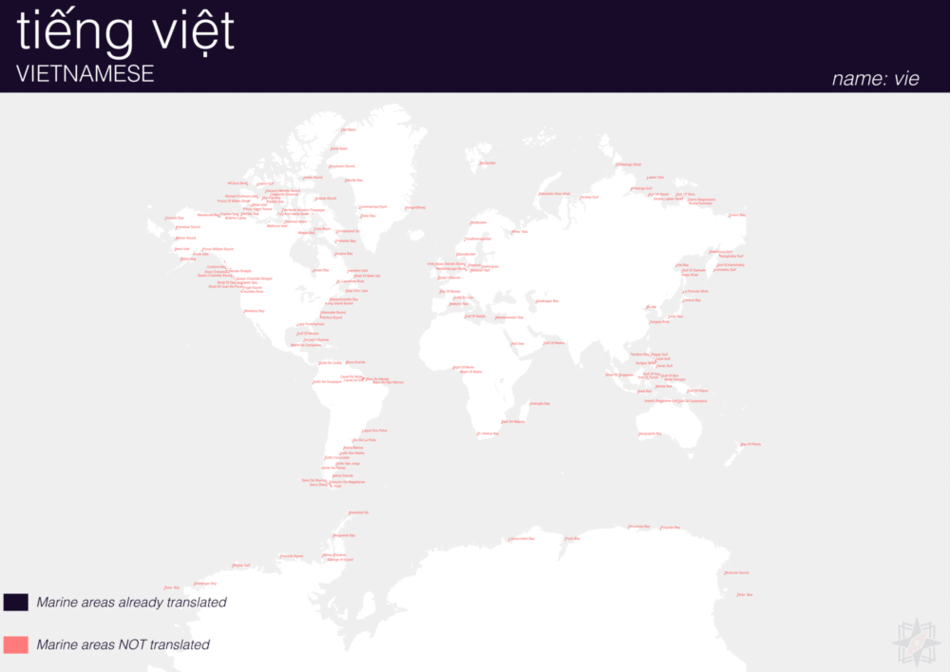
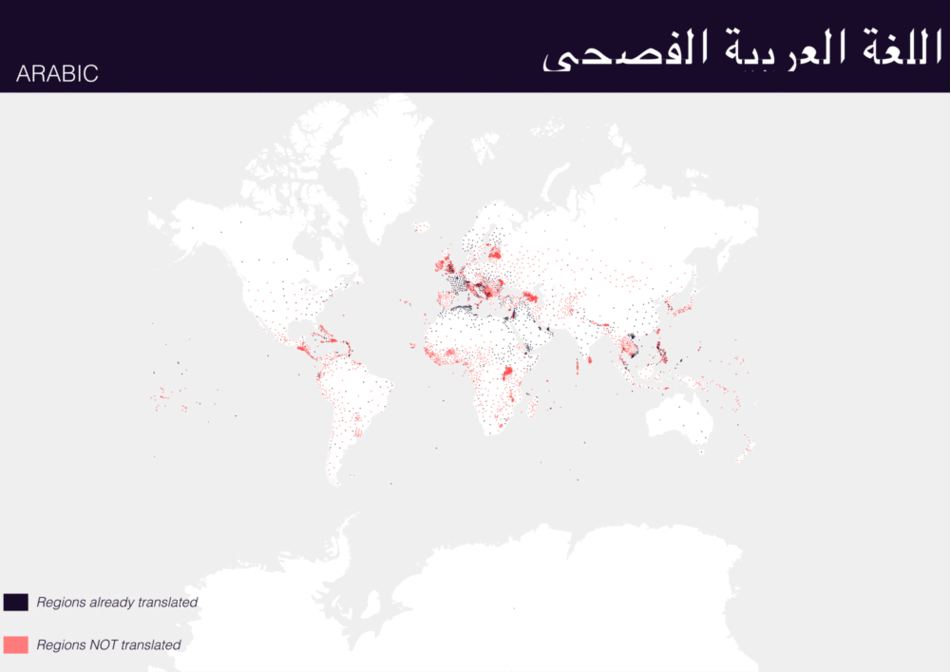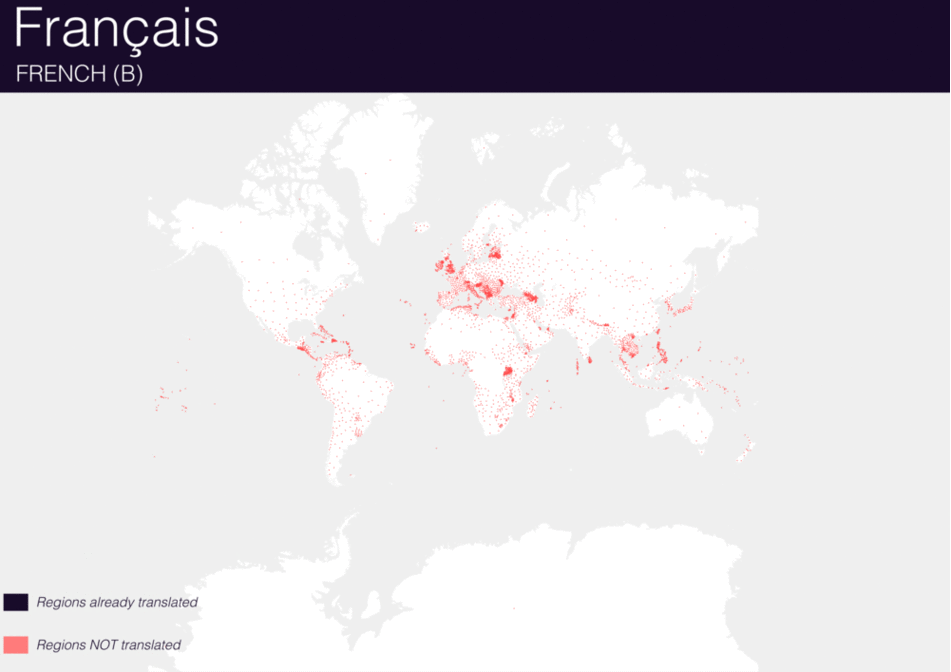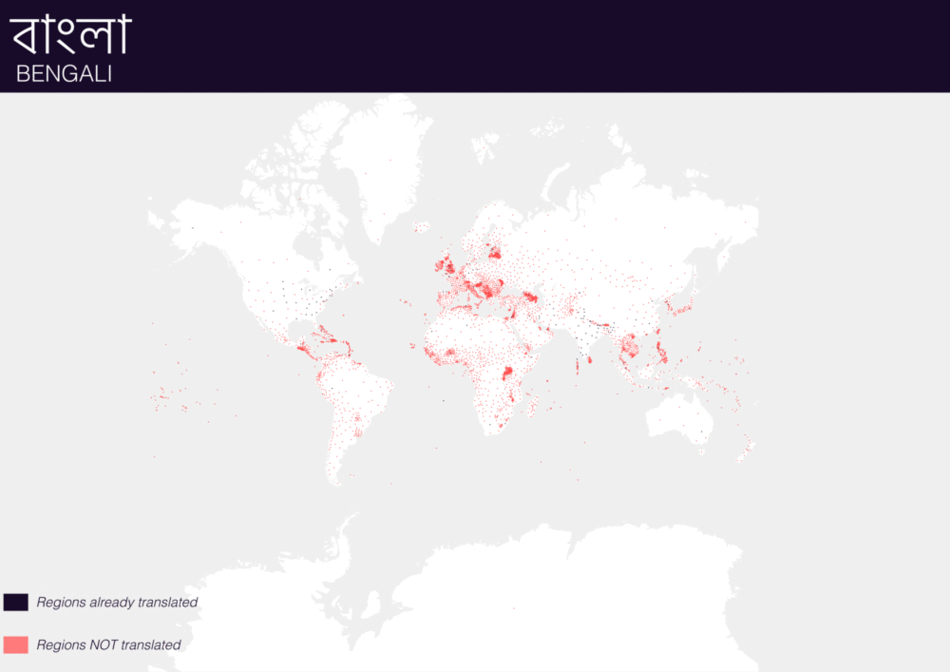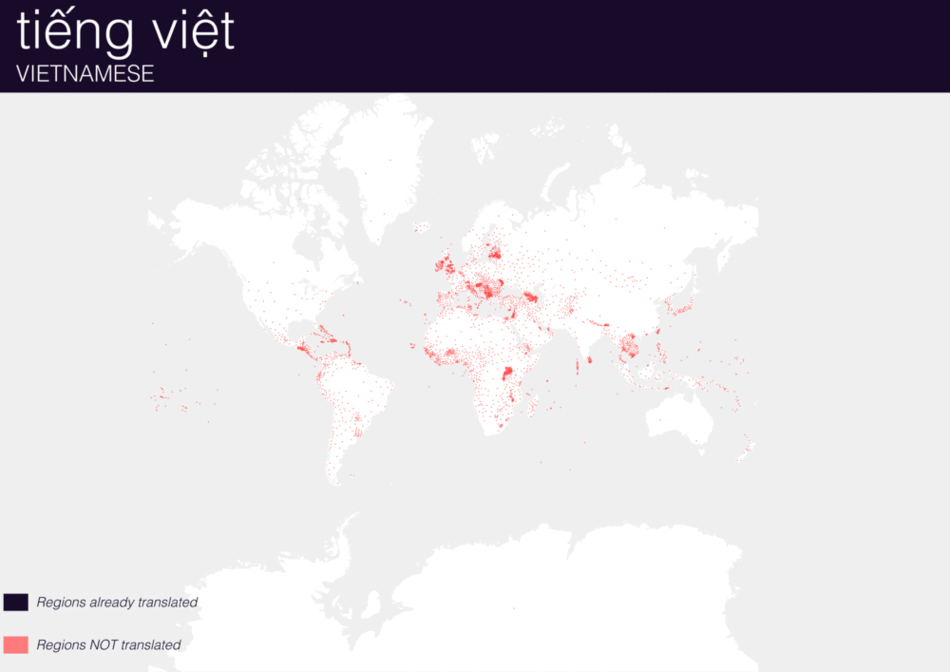
Using QGIS, I was able to import and style featuress to show which had translations (dark purple labels) and which didn’t (red labels). The map below is categorized by placetype and depicts Who’s On First records that have translations for the twenty languages of interest:
Continents
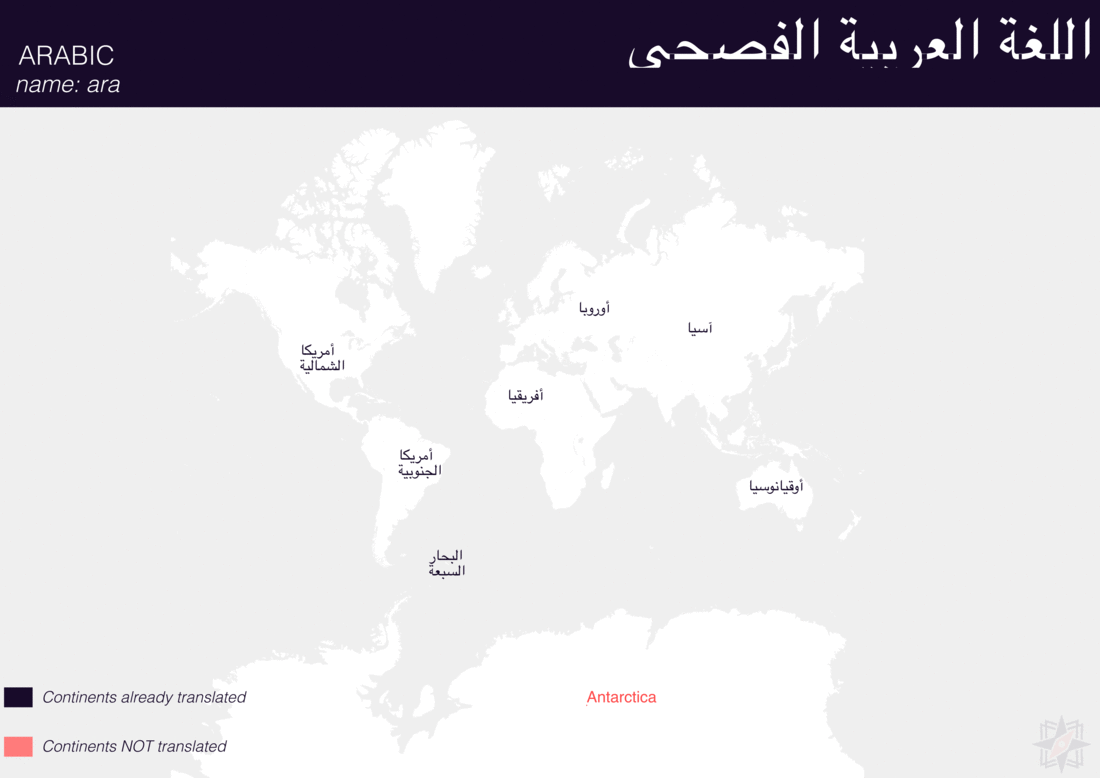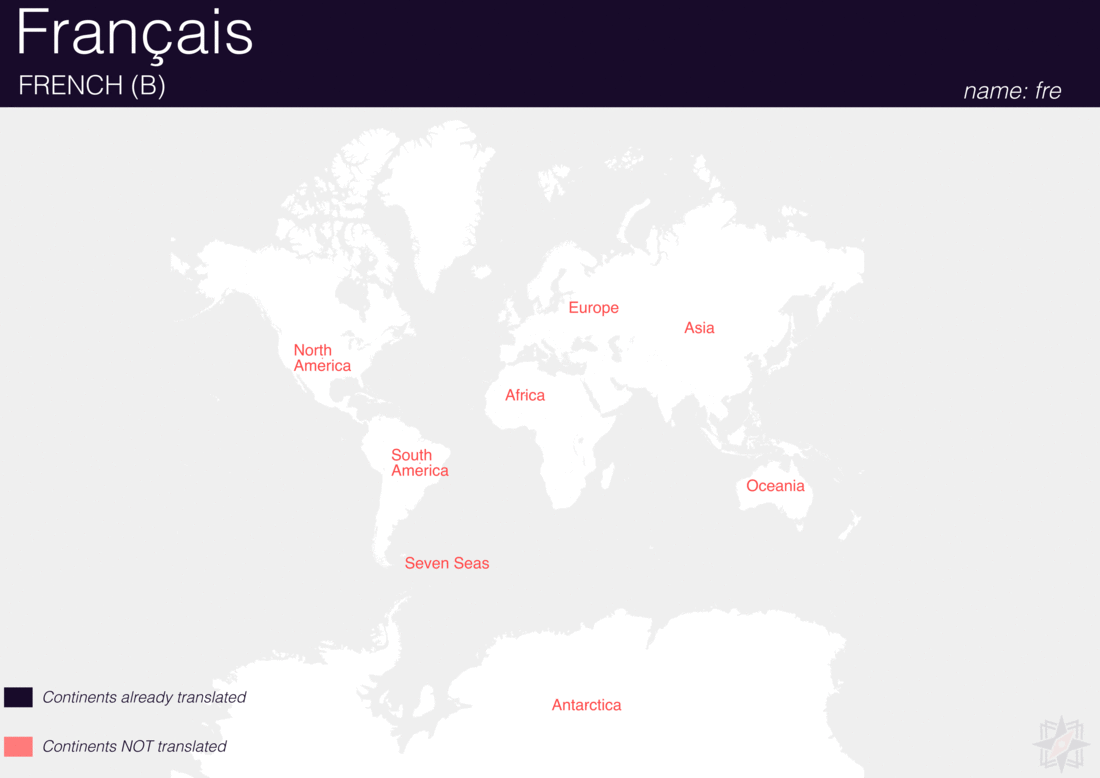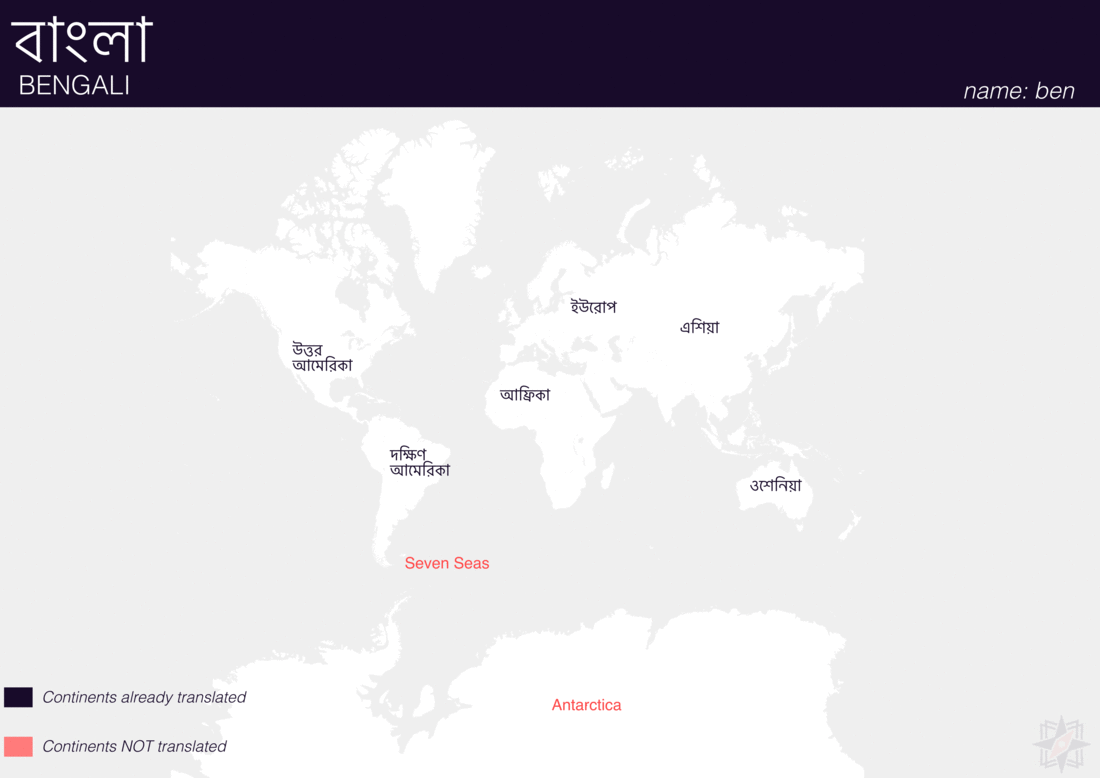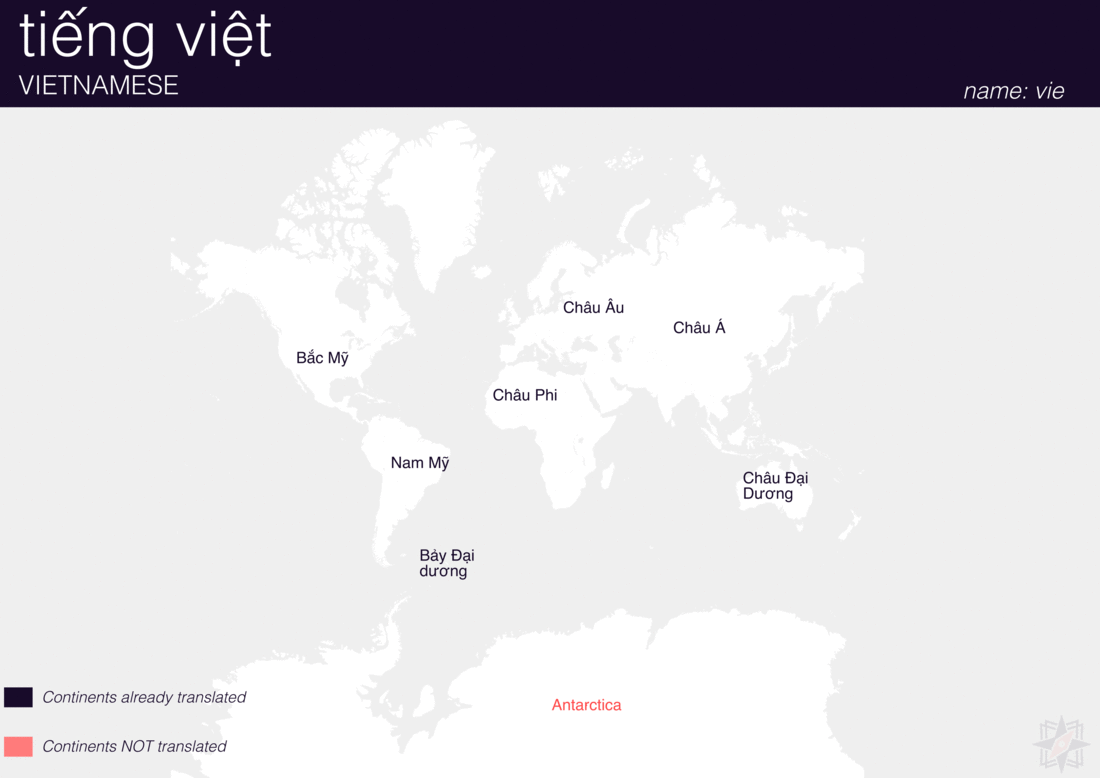
Here are additional graphics for the ocean, disputed, marinearea, and region placetypes.
Holding Hands with Open Data
While I was busy crunching numbers and charting, Stephen went prospecting for additional names.
Existing resources
Luckily, the open-source community has compiled many name translations. We can tap into these translations through concordances that exist in Who’s On First records. Websites like Geonames, Wikidata, Geoplanet, and Natural Earth, have exactly what we are looking for.
For each of these sources, a particular record will have a unique identifier that Who’s On First holds hands with. This allows us to augment our existing name translations. An important caveat — just because Who’s On First has a concordance value does not always mean we can extract data from that source. Often times, Who’s On First already has a name translation, or the source may not have any new names (or any at all).
Mapzen uses Who’s On First data in several services including Vector Tiles which powers parts of the Bubble Wrap map shown above (along with OpenStreetMap data) and in Search for both name lookups and reverse geocoding.
GeoNames
GeoNames maintains an alternative names file that contained roughly twelve million rows, each with data for a single unique and stable GeoNames identifier.
Using the identifier crosswalk in the Who’s On First concordance list, and after mapping the 2-character language codes used the GeoNames file to the 3-character ISO 639-2 codes used in Who’s On First, Stephen was able to pull out any names (and abbreviations) that Who’s On First did not already have.
Results
After Stephen added the new name: data to Who’s On First (and I cleaned up some names manually), it was time for me to see what was gained! To do this, I re-ran the same script used to generate charts on the repository to update charts and visualize the translation gains.
In total, over 113,300 records were updated to include over 255,000 new, unique name translations! While the majority of updated records gained one or two new name translations, this work filled large gaps in coverage for records that had zero name translations to begin with. For instance, a record for Easter Island gained over 100 new name translations!
From Occitan to Catalan to Persian, you’re now able to browse our records through our Spelunker tool to view these new names.
By placetype (overall)
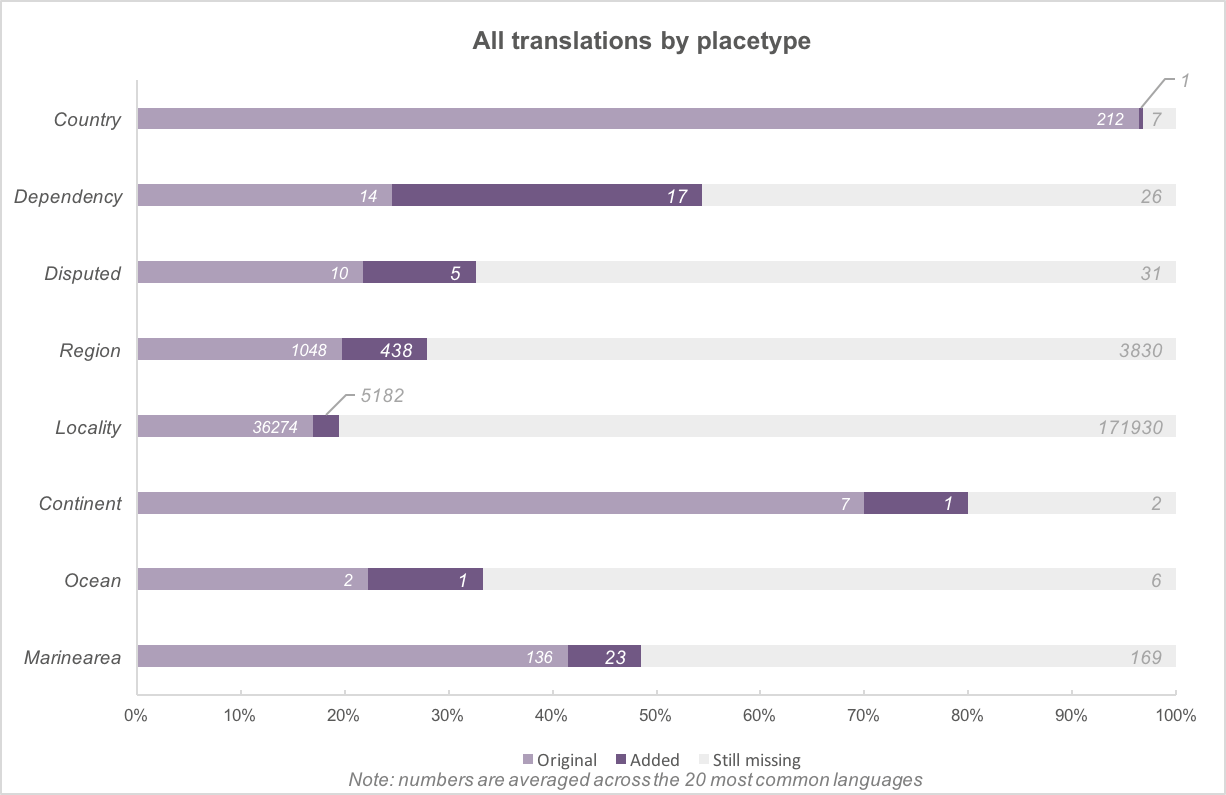
The chart above shows the total increase in translated names by each placetype. The light purple represents what I started with in the beginning of the summer, the darker purple is how many names were added, and the grey bar represents what is still missing. The numbers represent an average for all 20 languages.
Note: You’ll notice a discrepancy in the number of country records when comparing pre and post charts. The overseas insular regions of France (Reunion, Guadalupe, Martinique, French Guiana, and Mayotte) were reclassified from country records to region records in Who’s On First this summer, but don’t worry - these records gained new name translations, too!
By placetype, then by the six languages used by the United Nations (comparison)
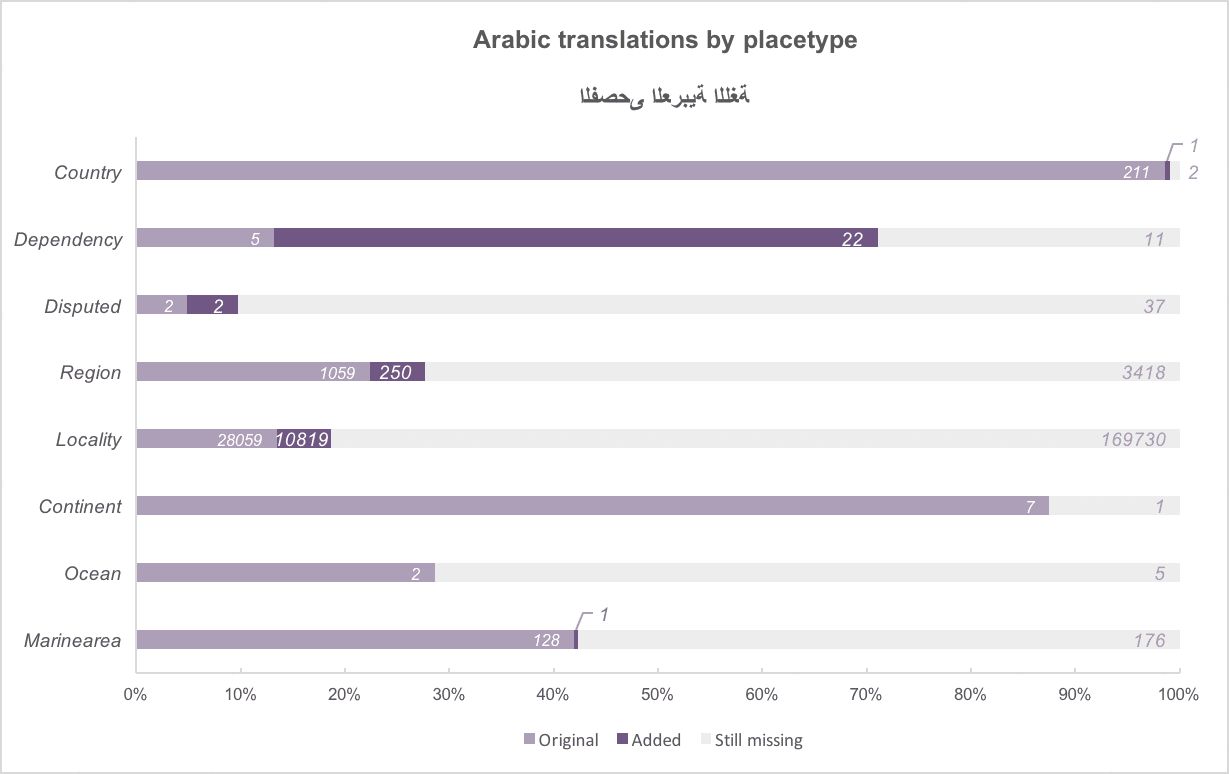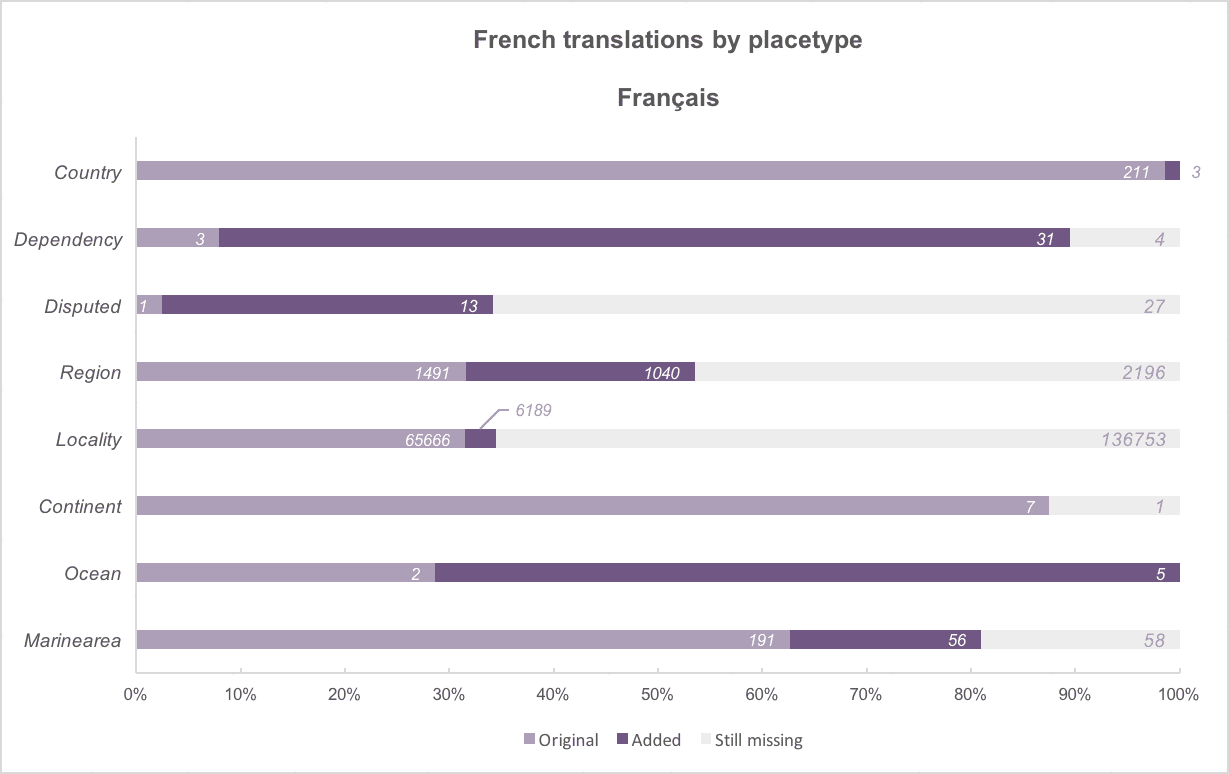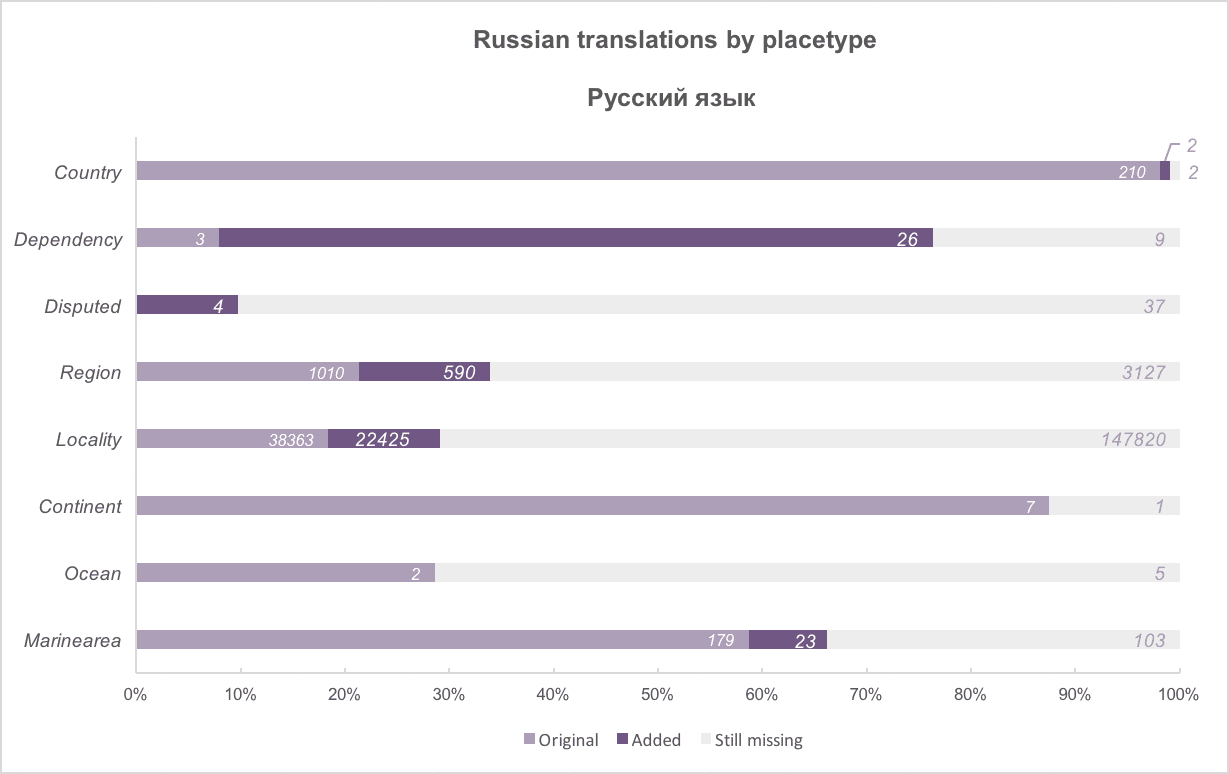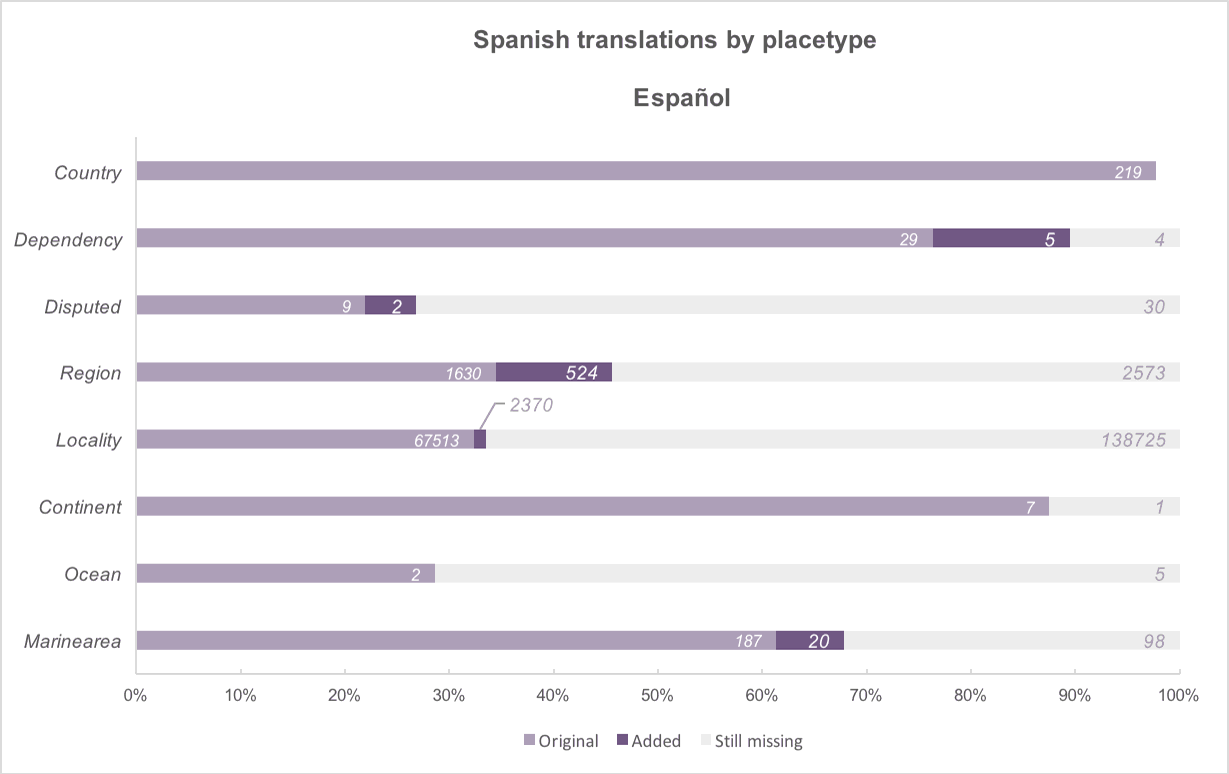
Above: The added translations, by placetype, for the six official UN languages. Work done for English translations resulted in 100% coverage across four placetype categories!
By placetype, then by zoom level (comparison)
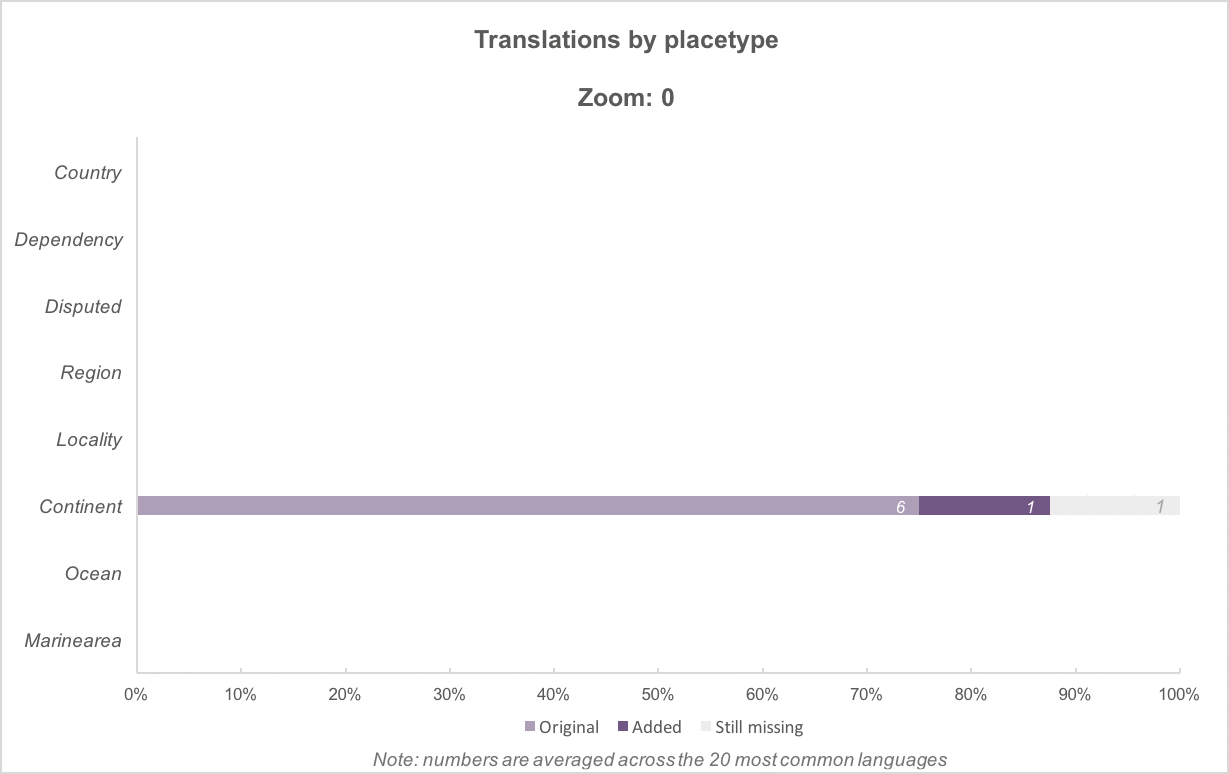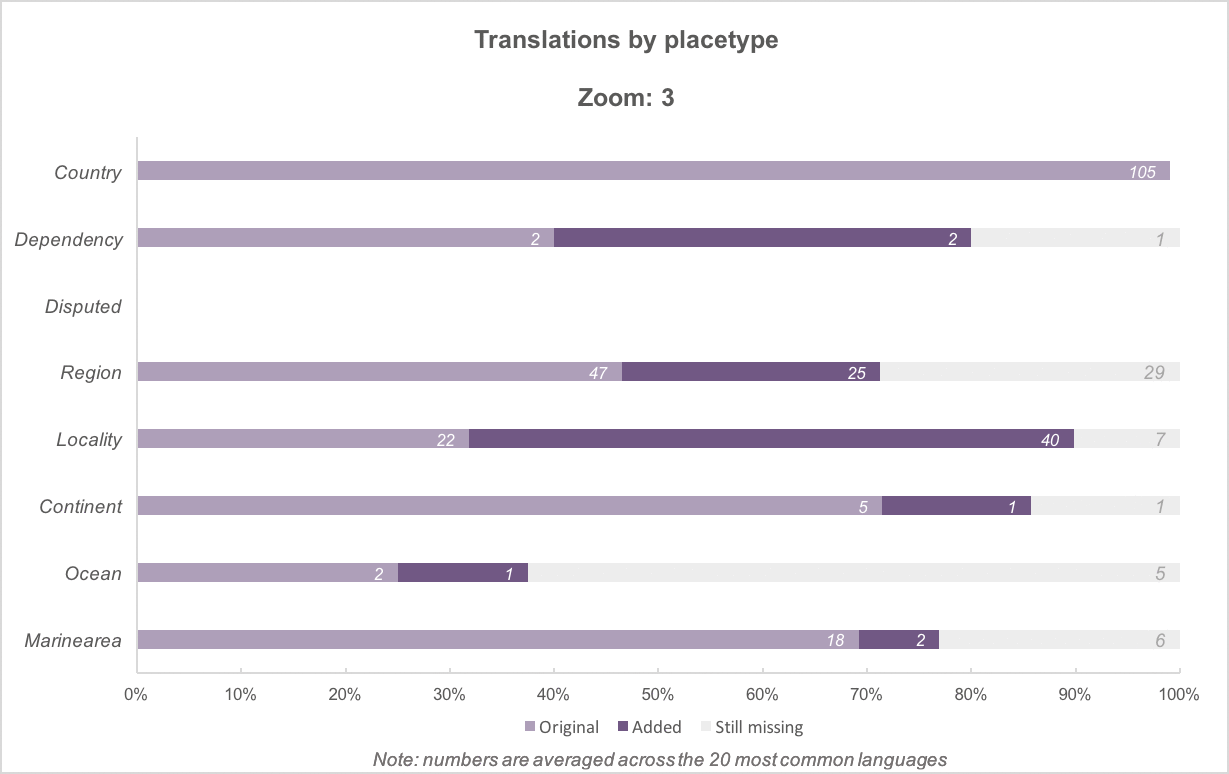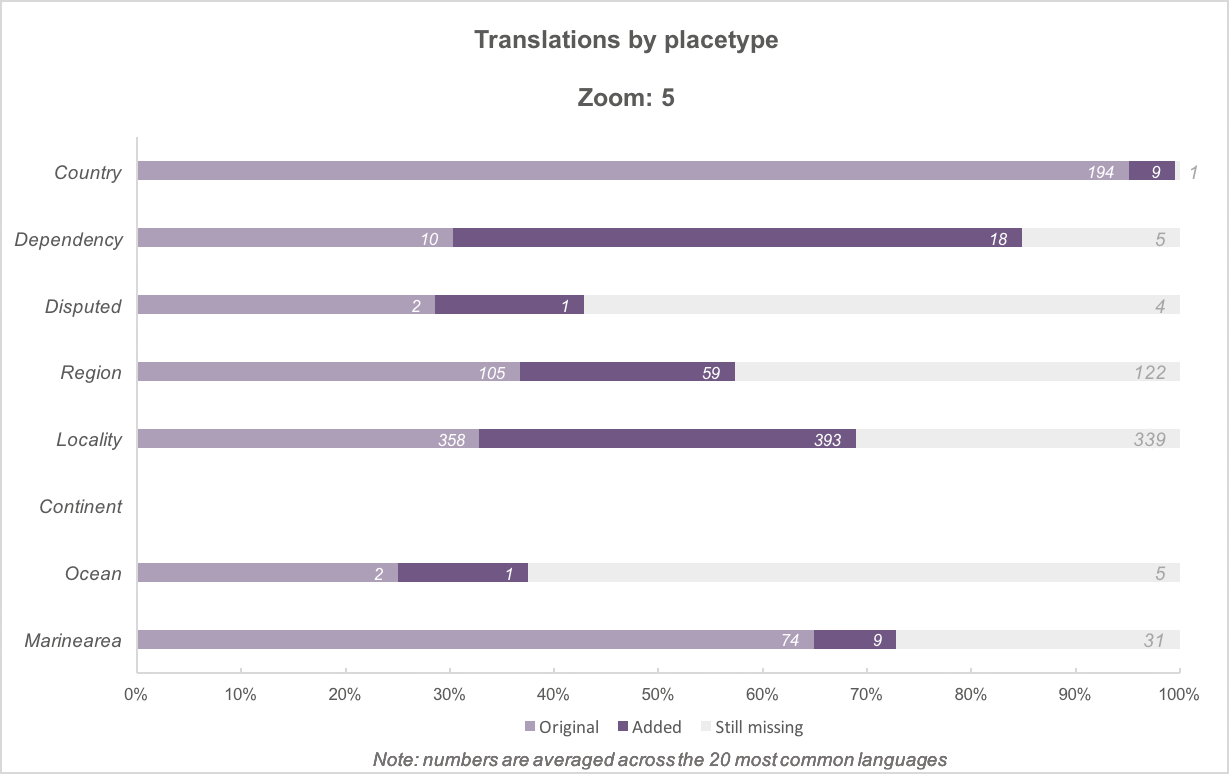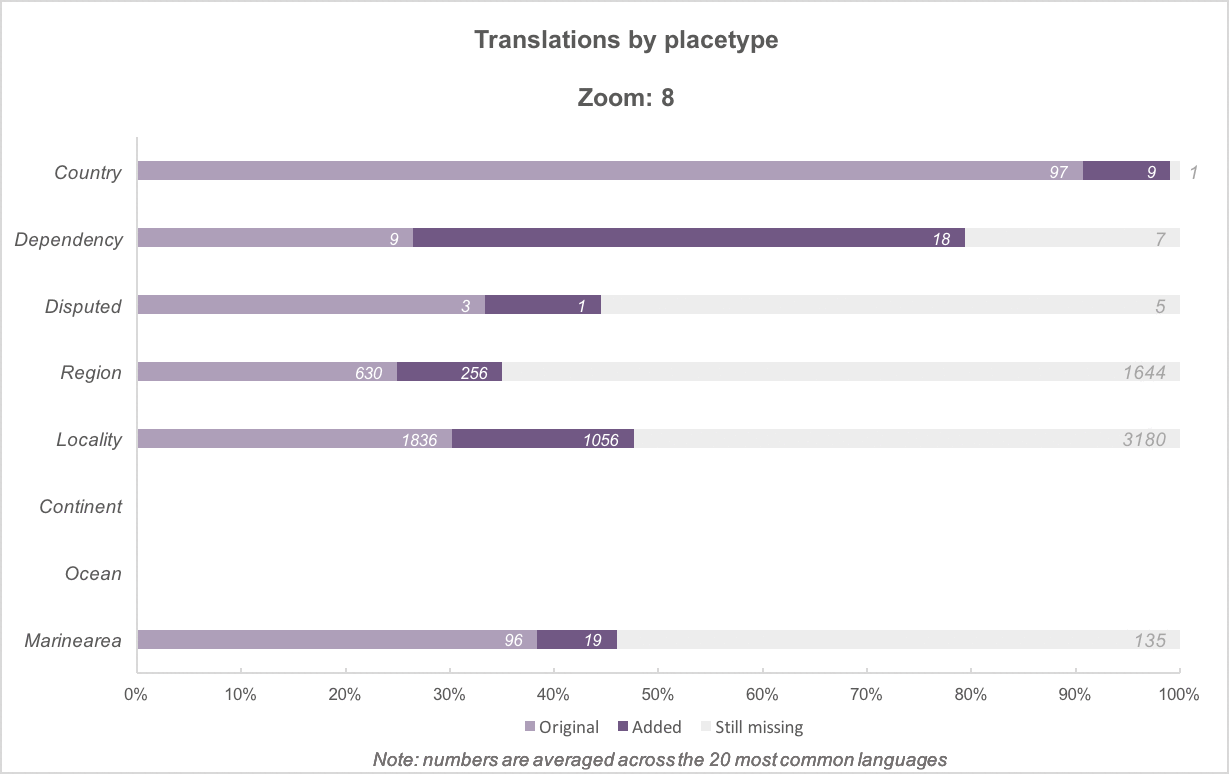
Above: Added translations, by placetype, for zoom levels 0 to 8. There are fewer placetype categories and a higher percentage of translated names at the lower zoom levels. At the highest zoom levels, translation percentages drop as more features become present. (Other charts in this post are equivalent to zoom 16.)
By language (overall)
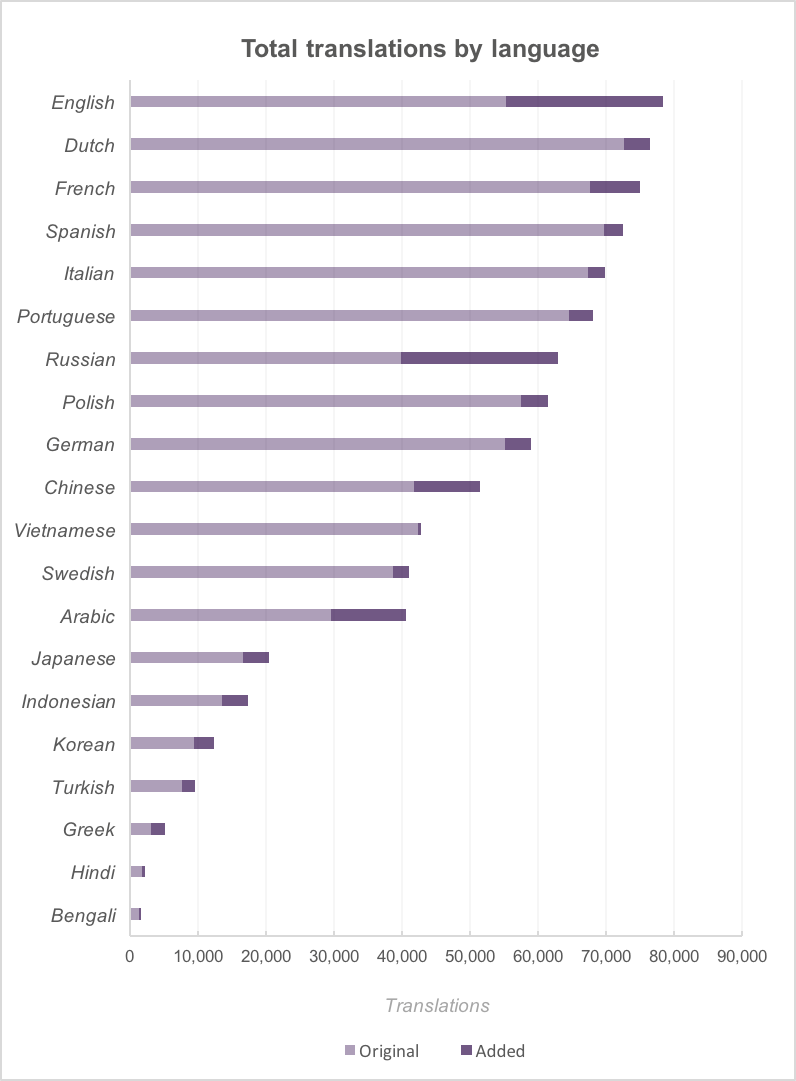
Above: This chart shows the total number of features with translations for all 20 languages we focused on. Dutch appeared to be the highest translated language before the summer, with an additional 3,800 name translations added, but was beat by English which saw larger gains.
What Did I learn?
Before beginning this internship, I hadn’t the slightest idea how I would translate millions of records into multiple languages. In fact, it was a rather stressful first week mauling over where to begin. However, with the help of some amazing colleagues I was able to narrow the problem down, and approach this more methodically. I learned first hand that the best way to eat a whale is one bite at a time!
This summer I gained some valuable experience writing Python scripts, dealing with large datasets, and create meaningful charts to help the data team. Aside from a single Python course last semester, I had never used programming in this way and the real world application has opened my eyes to the possibility of making this a career. Even though it wasn’t fancy, I spent ample time perfecting how to generate charts manually in Excel that would visualize the work. While there are many automated charting libraries out there, this allowed me to work closely with the data and fine tune how best to visualize it using a tool I was familiar with.
Additionally, I was introduced to using GitHub in a professional setting, which has been a frustrating, yet rewarding experience. I have come to understand version management, pull requests, and how to deal with merge conflicts, without pulling out all of my hair (beard hair to be specific).
I would like to thank my manager Nathaniel Vaughn Kelso for his vision regarding this project, as well as his confidence in my abilities. I also must thank Stephen Epps for his constant support and dedication towards my success. This project wouldn’t have been possible without their guidance and encouragement. For that, I am very grateful.
What’s Next?
As you can see in the charts, we still have areas of improvement in Who’s On First. We are now able to better visualize translations in Who’s On First using these charts, as well as a new feature in our Spelunker to filter by translations (see: for example, see the translations filter in the sidebar to find descendants of Africa in our Spelunker).
Mapzen has more concordance work, name imports, and one-off fixes planned, with an emphasis of increasing coverage by language, placetype, and zoom-level.
If you have names you would like to add to a record, please feel free to file a new issue in the whosonfirst-data repository or drop us a line!
Photo Credit: quiddle. (Flickr)


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}