 Illustration: Olga Kavvada. Photo Credits:
Wikipedia, Stay Connected
Illustration: Olga Kavvada. Photo Credits:
Wikipedia, Stay Connected
We recently tweeted that Who’s On First was “holding hands” with even more of Wikipedia. Today I will talk about how that work was completed.
To recap:
- 155,000 more Who’s on First records were linked up to Wikipedia
- 2 million more localized names (in multiple languages) were added for 135,000 Who’s On First records
Our vision is to be able to make a unique connection between our Who’s On First data and the corresponding Wikipedia page. Who’s On First is Mapzen’s gazetteer of places, each record has a stable identifier and descriptive properties about that place. We use Who’s On First data for several Mapzen services to help with labelling the map and improving search results.
Wikipedia is an encyclopedia which is collaboratively built by its users and has more than 5,000,000 articles covering many subjects and disciplines. The benefit of Wikipedia is that it has come to be one of the most popular websites on the internet, constantly evolving and one of the largest general reference works. Linking Who’s On First data to Wikipedia articles, allowing the two projects to “hold hands”, enables us (and you!) to benefit from this collective knowledge.
Wikipedia Structure
The first step is to understand the structure of Wikipedia’s database. Wikipedia has a web service API that provides access to its main wiki features, data and metadata, namely the MediaWiki API. An API is essentially a tool that allows software applications to talk to each other in a structured way.
To make things a little more helpful (or complicated!), Wikipedia has a related project called Wikidata that acts as a central storage space for all the structured data in Wikipedia. Each Wikidata record is uniquely identified and links to each related Wikipedia entry (think web page) in all the different Wikipedia’s languages (282 at last count!) for that entity.
For example, in the English language Wikipedia the page is Spain and in the Spanish language Wikipedia the page is España. As a result, in order to find the specific country (or city!) in the Wikipedia of your choice, you would need to know the language code of the Wikipedia site along with the title of the page in that language.
Since we’re interested in adding more localized names in all the languages to each Who’s On First record, we’ll look for the feature first by the name we already know it as, then collect and add the rest of the names from the many Wikipedias keyed off the Wikidata ID identifier. For Spain the Wikidata ID is Q29 and that record has entries for both of the articles mentioned above, and in many more languages. We’re lucky each project has unique identifiers for places!
Wikipedia Titles
To link up the projects, we needed to get the original Wikipedia titles of each Who’s On First record (for example the borough that is called Bronx in Who’s On First but named The Bronx in Wikipedia and the Queenstown locality in Who’s On First is named Queenstown, New Zealand in Wikipedia), the Wikidata ID of each entry, the Wikipedia url and all the localized language translations of each place. In addition, we wanted to get population data for the administrative places, elevation from the sea level, area and latitude and longitude coordinates. The entire code structure can be found in this repository as an iPython Notebook.
The first step of adding concordance between Who’s On First and Wikipedia data was to identify a connection point. Wikipedia allows you to search its database for a place name and returns the most likely Wikipedia page title. We used this API query to identify the potential original Wikipedia page title for all the administrative places in our database using the Who’s On First name as the key input argument.
A sample python request using the requests python package for the original Wikipedia titles (wk:page) is shown below:
request_API = ("https://en.wikipedia.org/w/api.php?action=query&list=search&srsearch=%s&srprop=title&srlimit=1&format=json" %name)
result_request=requests.get(request_API)
This worked relatively well but as you can imagine for the ambiguous cases (where multiple results could match) Wikipedia sometimes returned page titles that were not the ones we were looking for. We looked through the results and applied several cleanup steps to identify which ones were correct and which ones were not.
In the table below you can see a selected subset of the raw results that we got from Wikipedia wk:page for each Who’s On First wof:name.
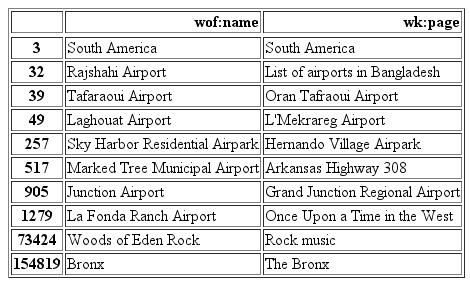
We used several approaches to sanity check the results and only keep the correct ones to prevent importing bogus Wikipedia concordances into the Who’s On First database. This involved a classification process to evaluate if the result name from Wikipedia was a good match for the input name from Who’s On First (correct column). The entire code for the data clean-up can be found in this iPython notebook.
The first approach involved identifying and discarding any Wikipedia titles that were included in a “blacklist”. This blacklist consisted of page titles that included numbers 0 thru 9 or any of the words timeline, birthday, political, environmental or music which would probably point to aggregate Wikipedia pages that were not of interest to us. This would help eliminate false Wikipedia concordances such as the ones listed below:
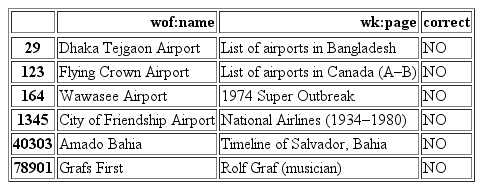
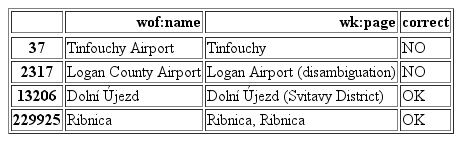
Another easy fix was to try and find results that were not referring to the same placetype even though their names might match. Such examples would be entries that did not have the word Airport or Facility in both the input name as well as the returned Wikipedia page. On the other hand, if the words District of Municipality were included in the returned result, they were classified as correct as we were looking for administrative places. Wikipedia sometimes returned the disambiguation page as a page title result which was disregarded.
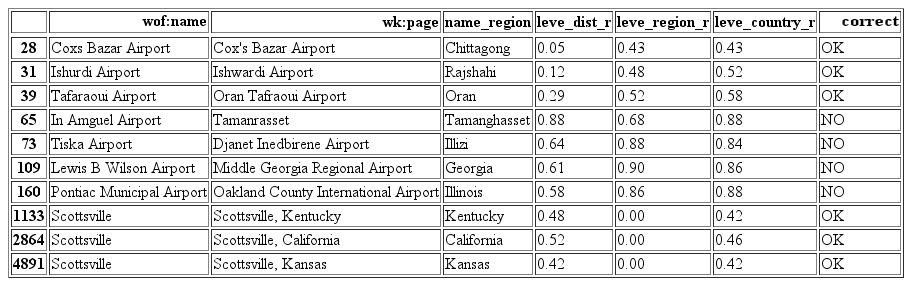
For the remaining results, we calculated the Levenshtein distance of the input name and the result name which is a metric for quantifying the difference between two strings. This value would be used as a metric for dissimilarities between the two names. To avoid misclassifying occurrences that involved some kind of hierarchical order (for example, Scottsville vs. Scottsville, Kentucky), we calculated a separate the Levenshtein distance between the Wikipedia result and the name after joining with its corresponding region or country.
The Levenshtein distance metric provided insight on which results were probably correct, thus their names were as similar as possible. We allowed entries that matched 100% with the Levenshtein distance metric but we were flexible enough to accept up to 30% dissimilarities (see Tafaraoui Airport example). Dissimilarities more that 80% of the strings were marked as not correct. Below you can identify some examples that were classified with the use of the Levenshtein distance.
Each of the Who’s On First records has an associated placetype that describes its hierarchy. A semi-automatic classification involved checking for placetypes in the Who’s On First data and the results from the Wikipedia page. The placetypes between Who’s On First and Wikipedia should match else the Wikipedia title was considered as wrong. In some cases multiple Who’s On First entries would share a name but have different placetypes associated with them (see example for China in the table below). For those cases the Wikipedia title was connected to the Who’s On First entry with the higher ranking of a placetype in the hierarchy of places (for example, country > locality > neighborhood).
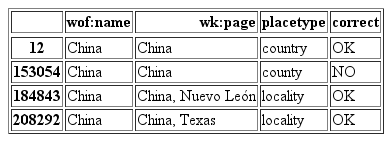
The final technique was to manually classify the entries as correct or not by going through the ones not yet classified especially in the areas where we had personal knowledge. The Slavic and Greek languages were classified by hand as it was impossible to find a point of connection between the different alphabets.
A snippet of the Wikipedia results and our final quality classification is shown in the table below:
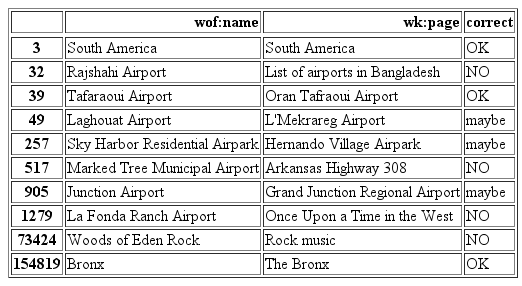
After cleaning up the data gathered from Wikipedia we ended up with about 155,000 of entries with Wikipedia titles classified as correct (OK in the table above), 24,000 were uncertain (maybe), and 81,000 were classified as wrong (NO).
Wikidata IDs
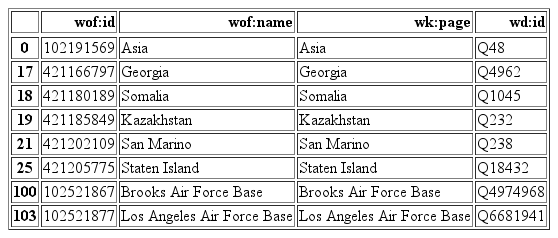
Having identified the correct Wikipedia page title for most of our entries we then requested the Wikidata ID for each page in our dataset. This returned a unique identifier for each entry that had an original Wikipedia title. These values are extremely useful as they provide a point of connection between all the different Wikipedias in the 282 different languages where the data is stored in a structured way.
A sample python request using the requests python package for the Wikidata IDs (wd:id) is shown below:
request_API = ("https://en.wikipedia.org/w/api.php?action=query&prop=pageprops&titles=%s&format=json" %name)
result_request=requests.get(request_API)
We also requested the word count of each web page from the Wikipedia API. This will help generate a quantifiable metric for assessing the importance of each place and will be described in a future post. A sample python request using the requests python package for the wordcount is shown below:
request_API= ("https://en.wikipedia.org/w/api.php?action=query&list=search&srsearch=%s&srprop=wordcount&srlimit=1&format=json" %name)
result_request=requests.get(request_API)
A subset of our Who’s On First data with the corresponding Wikidata IDs is shown below:
Wikipedia languages
Another important feature we were interested in getting from Wikipedia was different names in many languages for each Who’s On First record. Wikipedia has been designed in many different languages and also gives aliases to names for localized languages. This information is be valuable for labeling places on a map and for search engines.
The average number of language aliases for a Wikipedia place was 15 and some places had up to 266. Because some entries had so many Wikipedia aliases several consecutive API calls had to be made to get all the aliases for each place as each request only returns a small number of aliases at a time.
A sample python request using the requests python package for the languages is shown below:
request_API= ("https://en.wikipedia.org/w/api.php?action=query&titles=%s&prop=langlinks&format=json" %name)
result_request=requests.get(request_API)
Here are a few of Yosemite Valley’s different language aliases:

Wikipedia demographics and location data
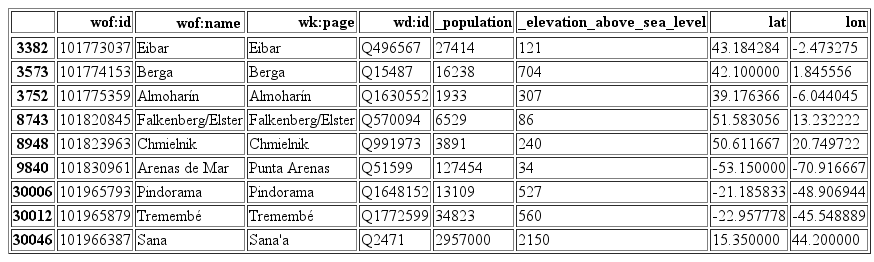
For administrative places, it would be great if we could add more information on population, elevation from sea level and location coordinates. Since this data cannot be directly accessed from the MediaWiki API, we used Wikidata’s SPARQL API query service. By using SPARQL we were able to get population, elevation and location data for some administrative places in Wikipedia.
The bottleneck of this process is that Wikipedia categories are not well defined so it is hard to search for all administrative places as they can be under many different categories. We searched for the most prominent ones like country, region, county, city, town, village, neighborhood, airport and archaeological site and then by using the Wikidata IDs joined them to the administrative places in Who’s On First.
Using this technique we were able to add population data to about 5,500 records in Who’s On First, elevation to 10,000 and latitude and longitude to about 26,000.
We love our data! (but it can always be improved…)
Wikipedia is a huge source of information and we are proud to have the Who’s On First gazetteer “holding hands” with more of it.
Of the 155,000 Who’s on First records that were linked up with Wikipedia, almost all Wiki places were in multiple languages. This allowed us to add nearly 2 million localized names for 135,000 Who’s On First records. A smaller set of records received some additional properties. For example, see Italy, where all the localized names are under the tab names and the Wikipedia concordances under wof - concordances.
You can see the full effects of the new Wikipedia data in Who’s on First by using the Spelunker to view lists of all the Who’s On First places with:
This is still a work in progress and as new data comes into Who’s On First we will need to keep our Wiki concordances fresh.
We wish to use this data for other types of analyses as well, such as a ranking method of feature importance to help mapping and search. We will keep you posted!

{kind=link}