Mapzen is expanding!
As Mapzen continues to grow – both in users of the various platform services and in the services we offer – geo distribution of those services becomes a necessity. While we strive to edge cache as much content as we can, there are various scenarios that necessitate origin servers in regions across the world.
While simply building new application servers in other regions is not an incredibly complicated task, it doesn’t address a multitude of other issues that arise when building infrastructure in multiple AWS VPCs that have no private network interconnectivity. Namely, what do we do about monitoring infrastructure, cases where we have database masters in a single region that we need to talk to from all regions, and all the other edge cases that arise?
We remain cognizant of the fact that ideally, infrastructure in every region would be autonomous, but the reality is that there will always be situations that may require one of those regions to talk to another. One option is of course to tunnel those communications over the public internet. This would necessitate that those applications had an easy means of encrypting traffic, which isn’t always the case. It would also mean opening up holes in security policies to allow the inbound communication, which carries with it a number of additional concerns. Rather than manage this sort of thing at the application level, we decided a global secure tunneling solution would be preferred.
This post will give a little taste of the theory and execution behind our setup. It’ll be light on specific details, mainly because it’d be pretty tedious for me to write and you to read! But if you want to discuss the finer points of the implementation, please get in touch.
The Theory
There are a number of useful posts out on the web detailing, to various degrees, how to use openswan to connect AWS VPCs. After evaluating a few other software based solutions, we decided to stick with the general KISS principal and build a setup using openswan as well.
In addition, we elected to designate a ‘primary’ VPC, which could talk to all other regions we build and which all those regions could talk back to, but not to mesh all the other non-primary VPCs. Reducing the mesh reduces the complexity enormously, and we had no use case that would warrant doing it.
When building out the new VPCs, we also tried to maintain consistency in network addressing: 10.[even number]/16 subnets would be production, 10.[odd number]/16 subnets would be non-production. These small details become very important as your infrastructure continues to grow… don’t discount them as insignificant!
How it looks
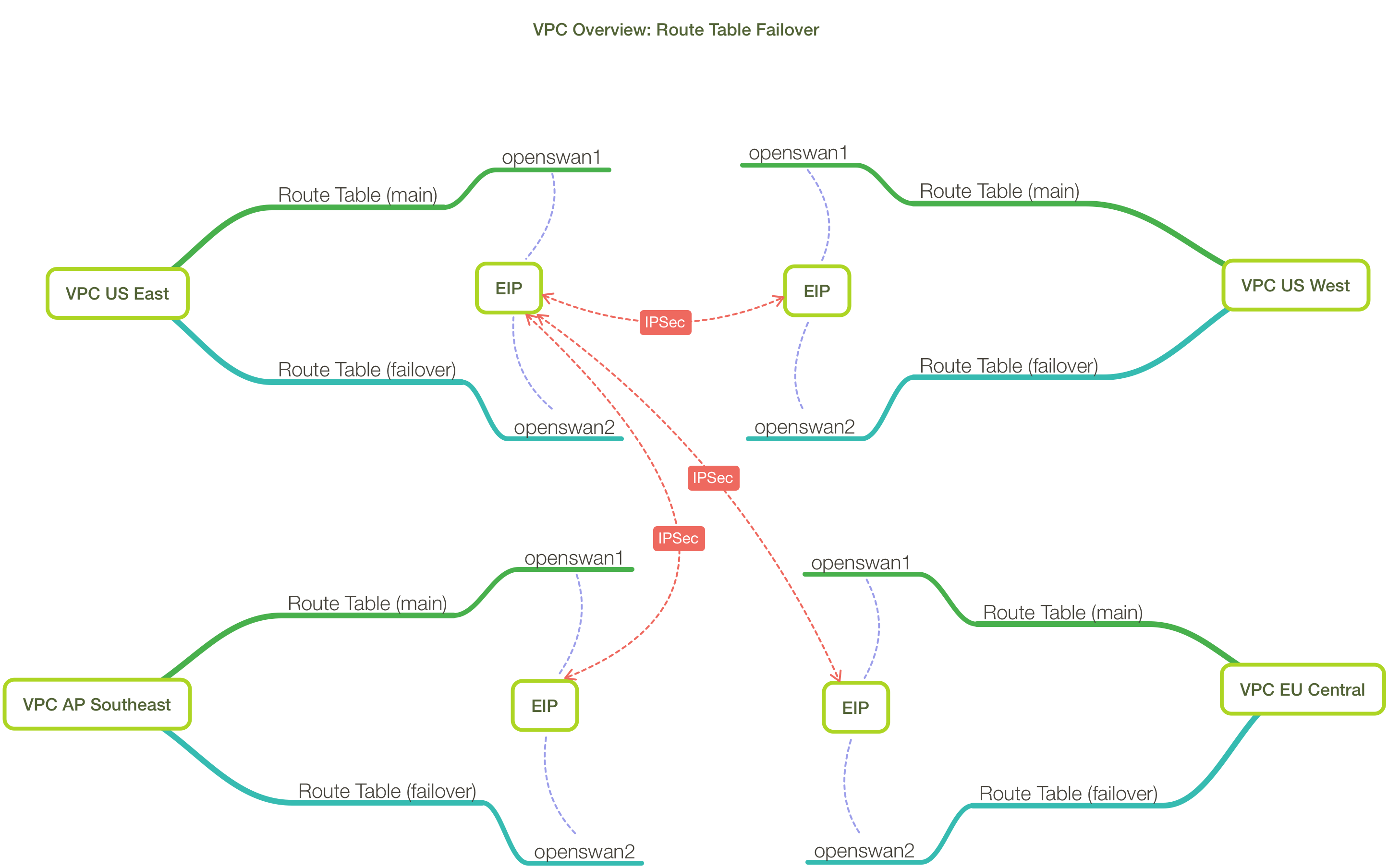
In each region, we have two systems running openswan. One is assigned an EIP at any given time and acts as the primary system through which traffic from another region or regions in flowing.
There are a number of, shall we say, interesting tweaks needed to these instances to allow all this to work. One example is MTU size, at least in our configuration where we’re allowing traffic to flow from production to non-production VPCs over an AWS VPC peering:
*mangle
# Fix mtu craziness when tossing data around in ipsec tunnels
-A POSTROUTING -o eth0 -p tcp --tcp-flags SYN,RST SYN -j TCPMSS --set-mss 1300
Each VPC has two route tables, a primary and a failover, as we’re using static routing. So each route table knows to route traffic for each VPC through one of the openswan instances in its region. Obviously only one route table can be in use at any given time, which is where monitoring and failover come into play…
Monitoring and Failover
# get instances and eip from the stack
#
def get_instances(stack_id)
client = Aws::OpsWorks::Client.new(region: 'us-east-1')
resp = client.describe_instances(stack_id: stack_id)
...
# associate a specific route table with all the subnets
# in a region, overriding the main route table.
#
# examples:
# failover_rtb(rtb_failover, subnets, region, false)
#
def failover_rtb(routetable = '', subnets = [], region = '', dryrun = true)
client = Aws::EC2::RouteTable.new(region: region, id: routetable)
...
We wrote a bit of monitoring infrastructure code (sampled above), in the form of a Sensu subscriber check which all these systems run. The check determines what region it’s being run in and whether it’s being run by the primary (EIP assigned) system or not. With that information, the systems then ping the other regions to ensure that connectivity always exists. In the event a failure threshold is reached, a failover is initiated: the EIP is swapped to the other openswan instance, and the matching route table for the VPC in question is enabled. In the interim, informational alerts are generated to let us know this has occurred, but guess what? We don’t have to do anything to intercede! (And who doesn’t love that kind of automation?)
Conclusion
So that’s the thousand foot overview. As mentioned earlier, if you’re interested in more details, get in touch, and conversely if you’ve implemented something similar we’d love to learn more about your setup. In the meantime, we’re enjoying passing encrypted traffic between datacenters strewn across the globe as we continue to build and improve our infrastructure.

{kind=link}