TL;DR: we’ve added a CSV import feature to Boundary Issues! Our web-based GeoJSON editor for Who’s On First is not available for public use (yet), but we’re still publicly documenting our progress out in the open. The more technical stuff with screengrabs comes after a bit of introductory context.
The territory is itself weird
Like many New Yorkers who grew up on the west coast, the subway system is endlessly fascinating to me. Our sprawling 24-hour transit is a source of pride, the subject of gripes and strongly held opinions, and maybe the most interesting venue for contemporary dance in a city well known for its performing arts.

Naturally, we love to map the subway here in NYC. There’s the familiar and practical MTA official map (whose evolution is also a subject of obsession) and its many opinionated variations. Two of my favorites are the prewalker’s essential tool, ExitStrategy, and BulletMap, a map optimized for transfers between the subway and bus networks.
All of this is to say, the “subway map” means different things to different people. And that is because the subway itself means different things, depending on whether or not you’re able-bodied, just looking to catch a show, or stocking up on fashionionable collectables.
Zooming in
Let’s isolate ourselves to just one subway station, let’s say the 36th Street D/N/R/W stop in the historically working class neighborhood of Sunset Park. You can find this useful metadata embedded within the station itself.

Let’s just stand back a little bit. Behold, there are restrooms here! (For those not familiar with NYC subway facilities, this is uncommon.)

Also included are more valuable hours-of-operation metadata, especially useful if you find yourself returning home from a late night out, looking for relief. (Either rush home before midnight or take your time and wait until after 5am.)
Let’s keep looking around this station. Oh man, check out these tile murals!

The designers. (Hover or tap on this if you want to blow your mind.)

The builders.

The riders.
Like all of the public art in NYC subway stations, we’ve got more good metadata here. (Shout out to Peter Columbo, whose name is misspelled on the plaque, but whose mosaic handiwork is also at 110th St and Lexington.)

Checking out the Wikipedia article for the station gives us an even denser picture of the station’s attributes. I am as fascinated by the train enthusiasts who obsessively compile this info, as I am by the train systems themselves. (n.b. I very much count myself as one of those weirdo train enthusiasts.)

Despite the impressive diagram illustrating how the station’s unused tracks are positioned, Wikipedia does not mention restrooms or public art. That there are restrooms, that the mural here is a great example of Social Realism, are facts that are just as valid and frankly more interesting than the latitude and longitude for this place. Lots of the nuance that captures why we should even care about places tends to get ignored by datasets that are considered comprehensive.
(There was once an app for finding NYC subway art, but it appears to have been discontinued.)
Zooming out
Taking our previous example at 36th Street, we could imagine systematically capturing the kinds and locations of public art in transit centers (we could also do the same for restrooms and other amenities).
This being a post on the Mapzen blog, I’m interested in how that information can make its way into our open gazetteer, Who’s On First. It’s important to caveat that this type of transit information has not yet been gathered and associated with our place records, but it could be. We have all the tools in place, and an extensible structure that can capture new forms of place nuance.
The trick is in how we encode the properties for each place record, and in particular how we keep those property names from conflicting with each other. As I wrote in my last blog post about Boundary Issues and property editing:
Instead of specifying a
tagsproperty, we usewof:tags, meaning it’s a part of the Who’s On First namespace. This lets us keep things that are common to all WOF records, likewof:name, separate from from Mapzen opinionated things likemz:categories
The namespaces for WOF properties act as a cue about the nature of each property: is it “general purpose” or is it an “opinionated assertion?” It also serves another purpose: where did this opinion originate from? If you see a property with sg:tags, that sg: prefix lets you know that the data came from SimpleGeo.
This system allows us to keep a property like wof:name (the name of the place, “36th Street”) distinct from public_art:name (the mural’s title, “An Underground Movement: Designers, Builders, Riders”). The namespaces assigns a kind of credit/blame for where a given detail originated from. We maintain a GitHub repository, whosonfirst-sources, that describes who is responsible for which properties.
(Quick side note: just to be especially clear, public_art:name is a fictional property name chosen for the purpose of illustrating the logic of prefixes and sources. Who’s On First has an existing convention of treating public art as a first-class place, rather than a set of properties that decorate wherever an artwork physically manifests itself. A helpful test for answering the question “is it a place?” is: can I ask someone to meet me there? As in, “let’s meet over by Fearless Girl.”)
{
"id": 404734187,
"fullname": "Yahoo! GeoPlanet (formerly Where On Earth)",
"name": "whereonearth",
"prefix": "woe",
"key":"id",
"url": "http://developer.yahoo.com/geo/geoplanet/",
"license": "http://developer.yahoo.com/geo/geoplanet/data/"
}
A Who’s On First source is composed of a short list of attributes like name, fullname, prefix, url encoded into a publicly accessible JSON file. We maintain a single list of all the sources, including The New York Times (prefix nyt), United States Census Bureau (prefix uscensus), and our own Burrito Justice, whose microhood, La Lengua, has gone on to become standardized in other mapping taxonomies.
The range of ways we might describe a place will differ vastly depending on interests and needs. Using property prefixes gives us a useful way to group those needs, avoid naming conflicts, and let them all cohabitate within a single WOF record.
Who’s On First: it’s not just data
One of our self-imposed design constraints is that we don’t get to choose your dev stack. This is why we publish everything as GeoJSON flat files instead of, say, a PostgreSQL dump file. If you use PostgreSQL/PostGIS, you’ll find a way to get the data into your tables.
For my work on Boundary Issues, our bespoke web-based content management system for WOF records, my Mapzen colleagues are the primary customer. However, they are not the only customer, and we are just starting to pull in outside contributors. (If you want to be a guinea pig, please get in touch!). A lot of my recent focus working on Boundary Issues has been about lowering the bar for contributing data.
WOF ❤️ CSV
While GeoJSON offers an amazing level of flexibility and compatibility for describing places, it turns out CSV is an even better format for expressing many places at once. First of all it’s just been around longer; FORTRAN 77 supported it in 1978. That longevity means it has support in a wide range of spreadsheet editors, from VisiCalc to Google Sheets.
Unlike JSON (or XML), data encoded into CSV format doesn’t require that you read the entire file before you can start parsing it. That means CSV files can get really really big, and your software will still be able to read a single row efficiently. There are drawbacks to CSV as well, chiefly among them is it’s harder to express nested information inside its columnar structure. It’s all a trade-off, and choosing the right data format to encode stuff in has everything to do with the circumstances at hand.
Six sections into the post and…
That brings us to the lede, buried under quite a bit of context and exposition: Boundary Issues now supports importing CSV files 🎉. This is important and not just for the convenience of editing WOF data outside of specialized geo-software (QGIS I love you, but your user interface is bringing me down). CSV support means Boundary Issues can now import more data into Who’s On First, from a wider range of sources. And more importantly, we can invite more people to edit within spreadsheet software they already have at hand, increasing the number of perspectives describing WOF places.
The world is wonderfully multifaceted
The territory means different things to different people. Depending on your perspective, the kinds of data that are captured about places may be missing, insufficient, or downright hostile. Who’s On First is opinionated—like all datasets, no collection is truly unbiased—but we hope to be aware of when we’re asserting our own opinions about places and create a framework where a polyglot of place-feels will be welcome.
The multifaceted maps we make simply reflect the weird and wonderful territory they represent.
Like the Internet, Who’s On First data is made of people. Those who have the capability to edit our raw data necessarily reflect themselves in those edits. They are present in the data through choices about which places get edited, and the types of nuanced assertions they make about places.
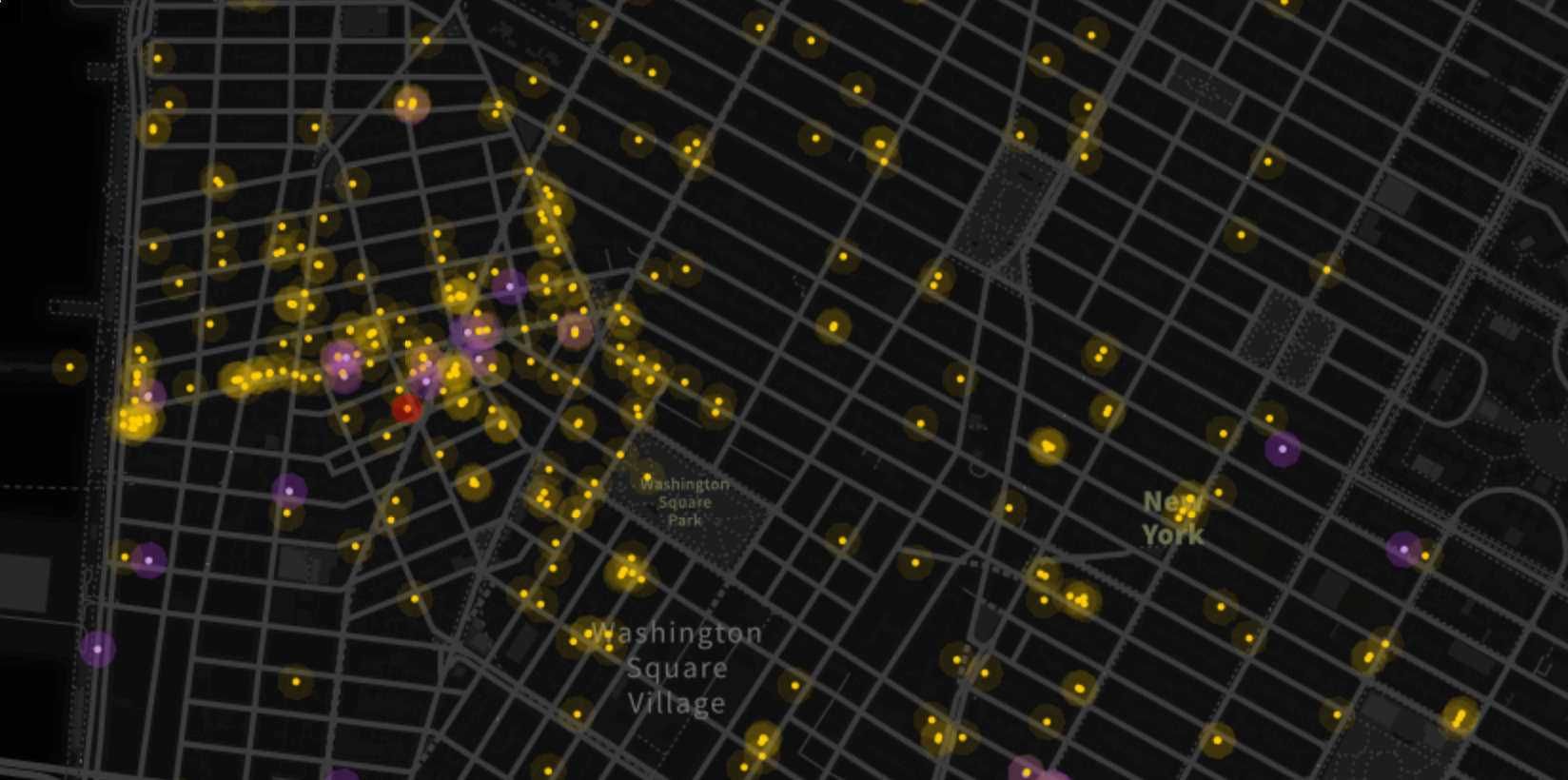
Throughout the development of the CSV import feature, I had the pleasure of working with Jeff Ferzoco’s dataset for his excellent historic mapping project, OUTgoing.
OUTgoing: The Hidden History of New York’s Gay Nightlife—is an effort to map documented historic locations of gay nightlife in New York City as far back and comprehensively as possible. We now have all 50 states with legalized gay marriage, and the LGBT experience is in the midst of a 21st century upshift. It’s time to look back and get some perspective and data—in order to look forward. From historic records, we’ve gathered 969 nighttime spots—bars, clubs, bathhouses, coffee houses, cruising areas, late-night diners, etc.—from the 1800s to 2015. It is nowhere near complete.
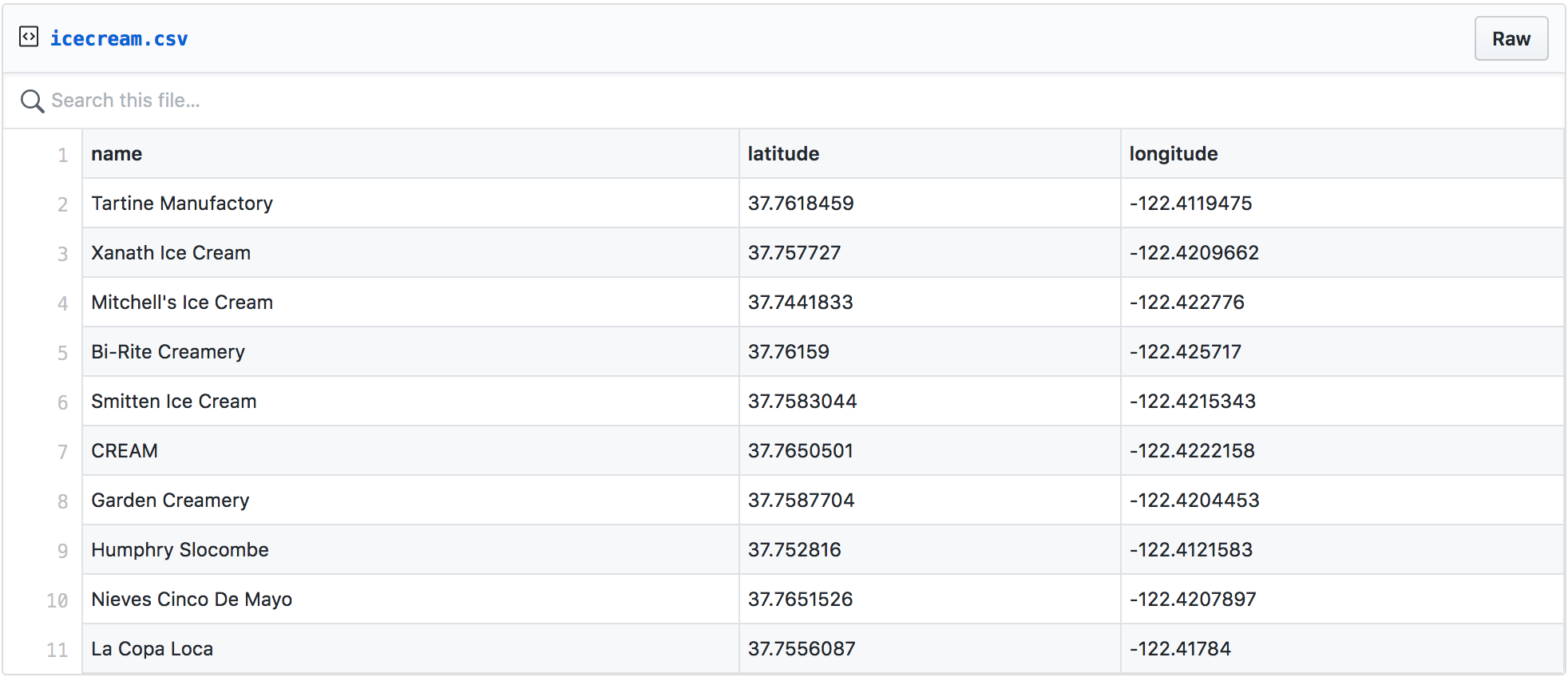
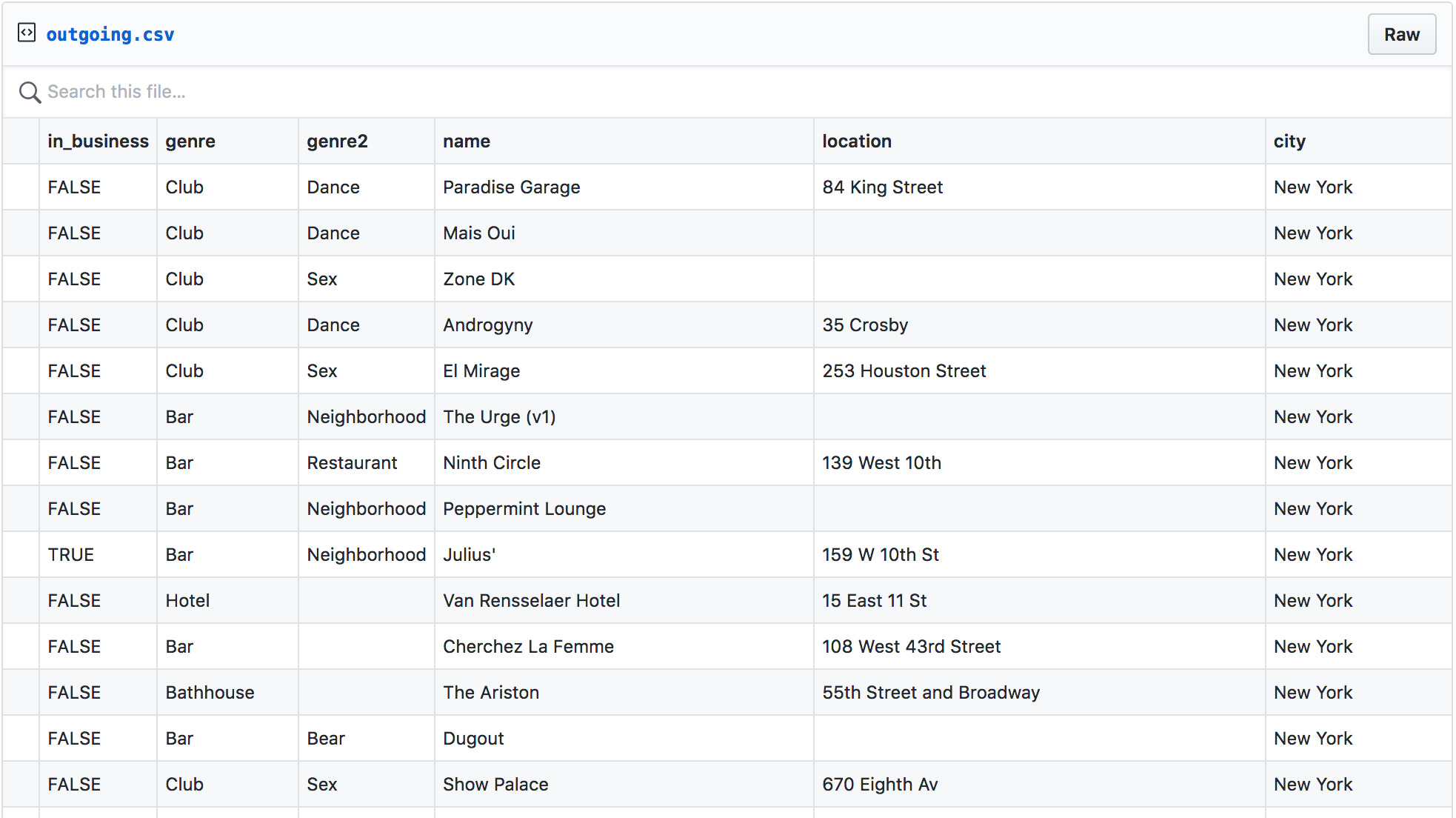
Jeff was kind enough to share a CSV file of all his collected places, which is dense with excellent metadata like year_opened, year_closed, and mafia_owned.
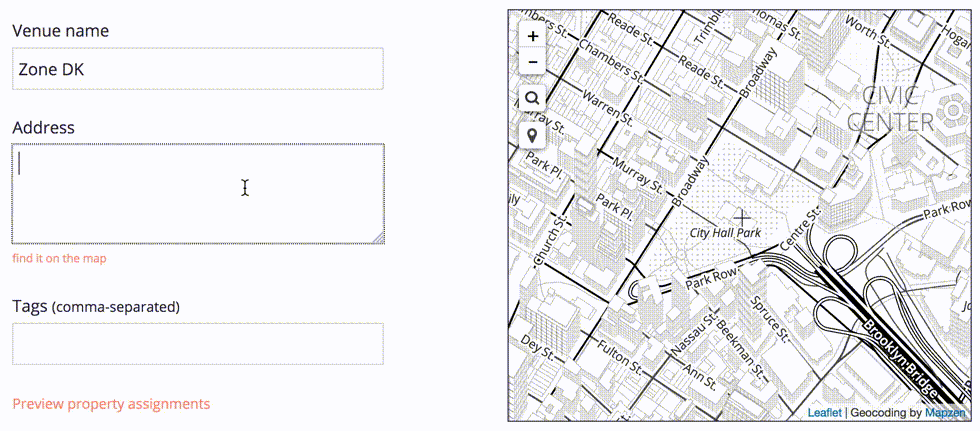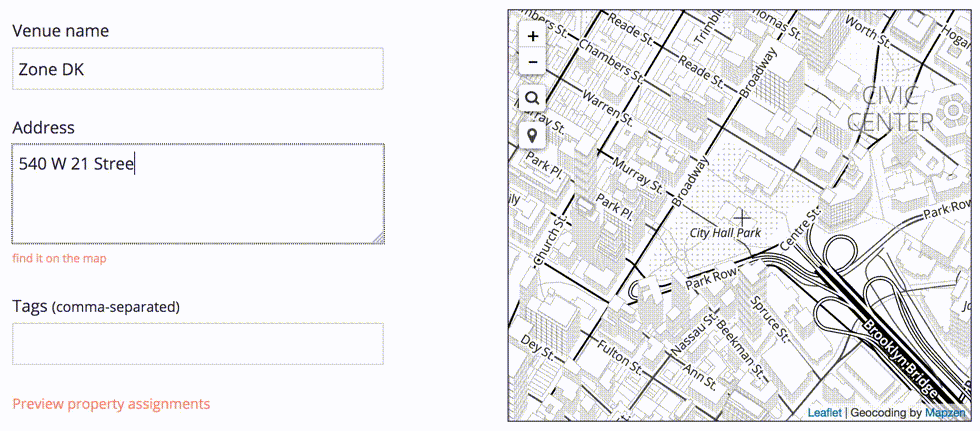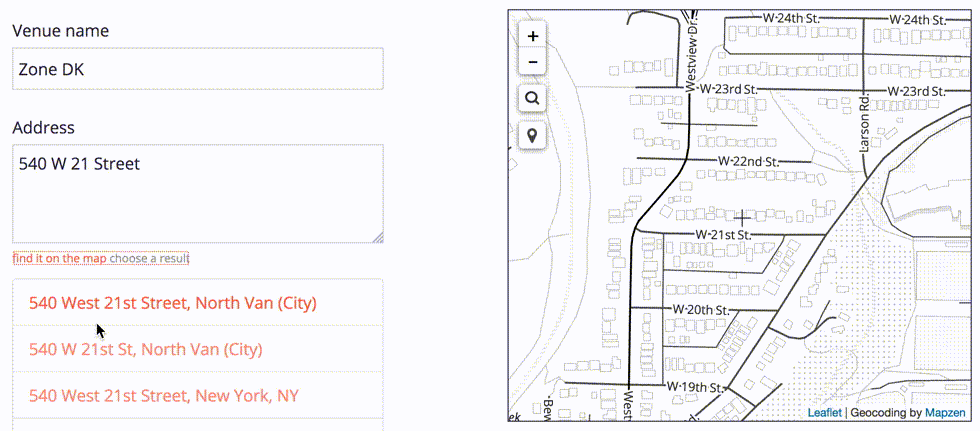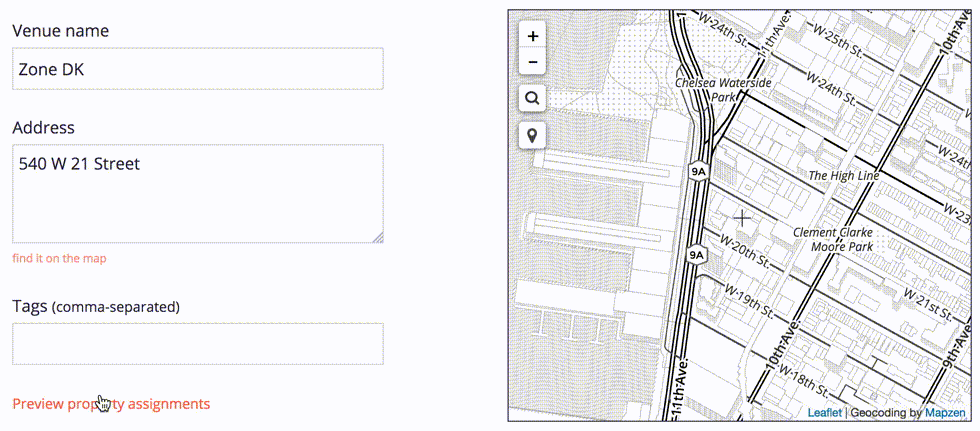
Here’s how we can start importing that data into Who’s On First: select the CSV file we want to upload.
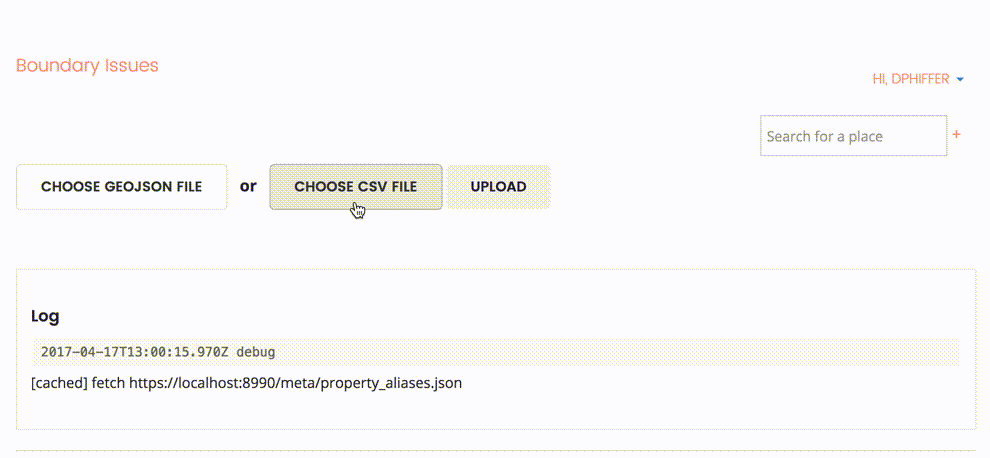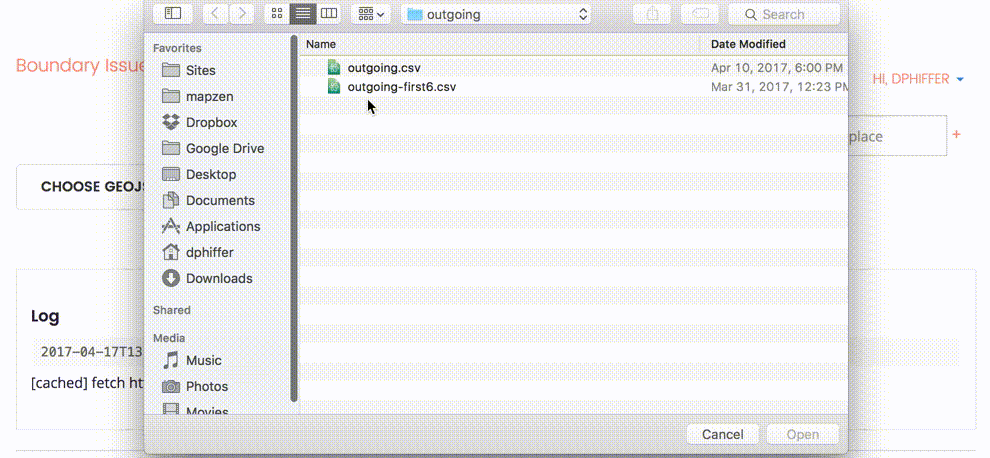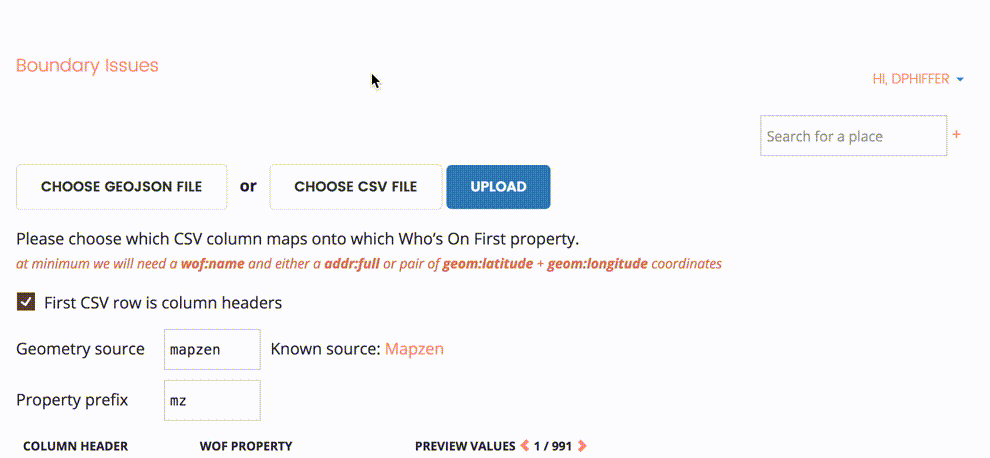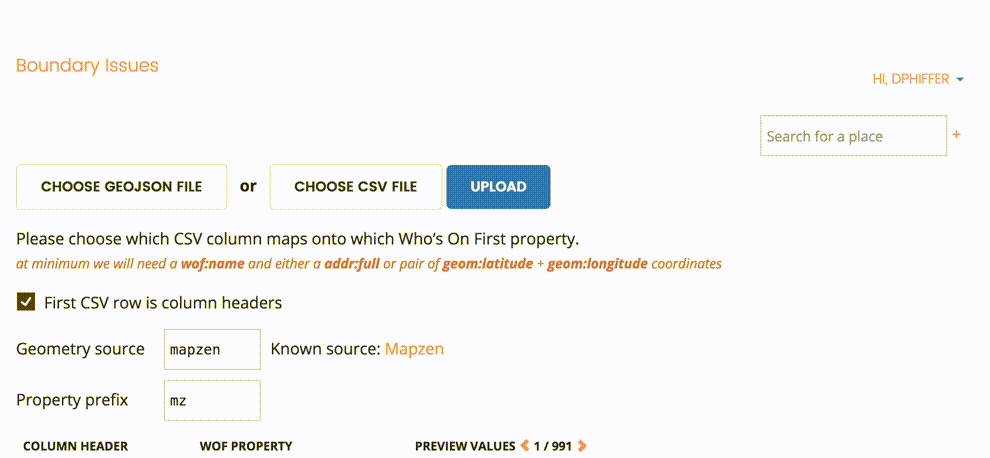
The upload interface reveals some general options, allowing us to specify whether the CSV file has a column header row, identify a source for the data (in this case, outgoing), and choose a prefix for the properties we are merging into Who’s On First.

Next we will map which columns should be saved to which properties. Some columns map onto generic, well-known WOF properties like wof:name, geom:latitude, and geom:longitude, while others get saved as new properties with the out: prefix. The code detects predictable column headings like latitude and longitude and maps them automatically.
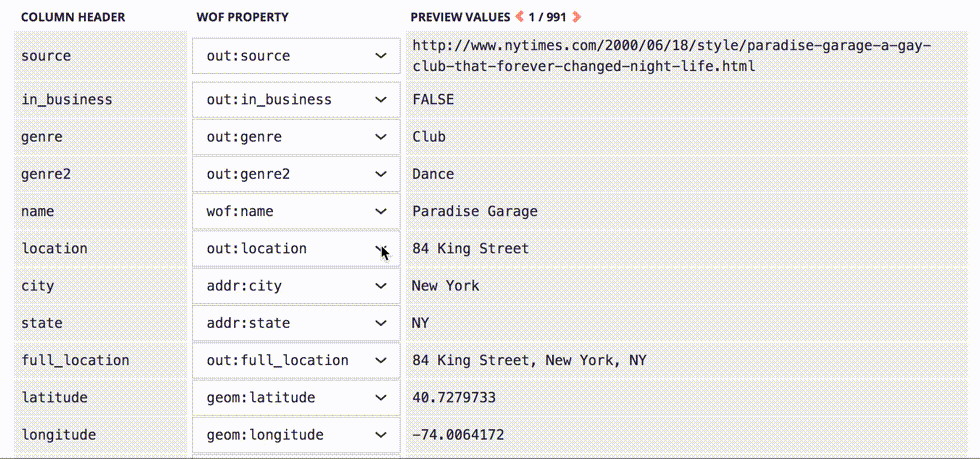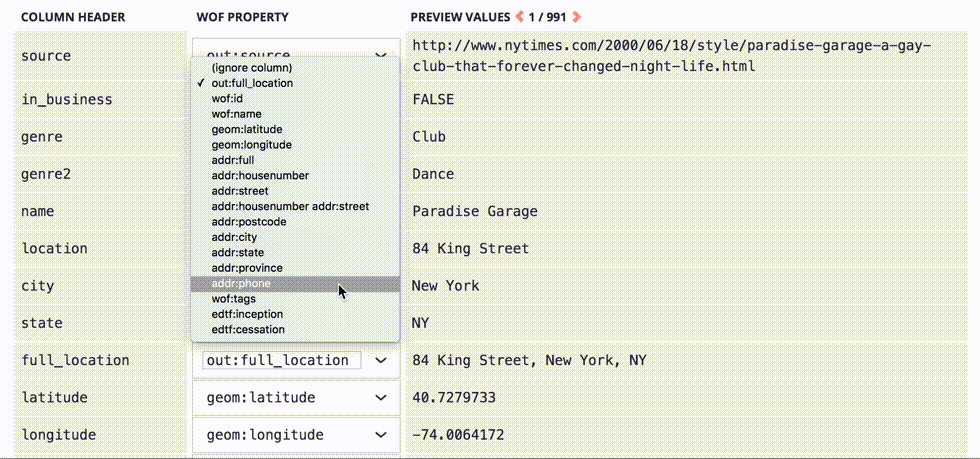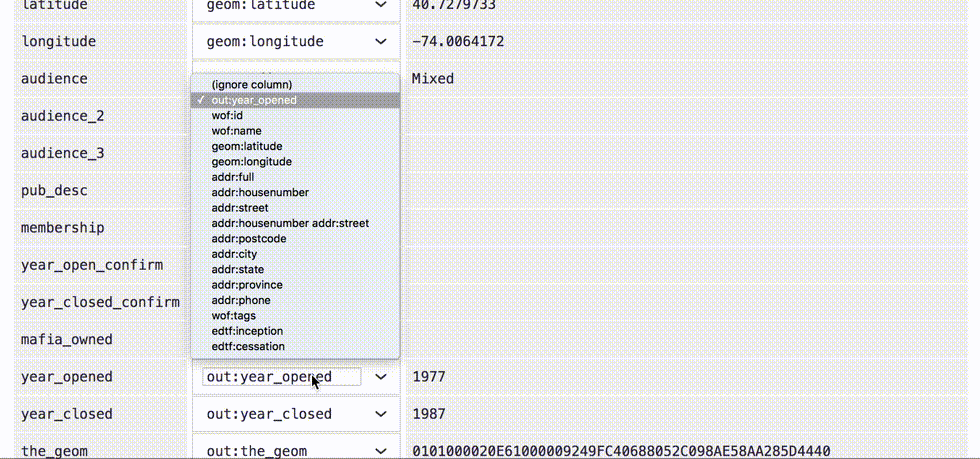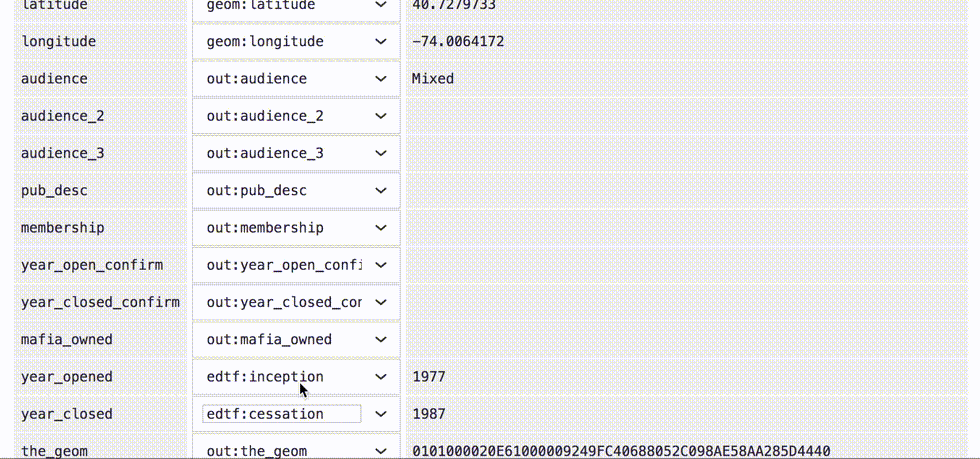
Once that property mapping is ready, we can click the “upload” button and begin stepping through each of the rows in the CSV file.
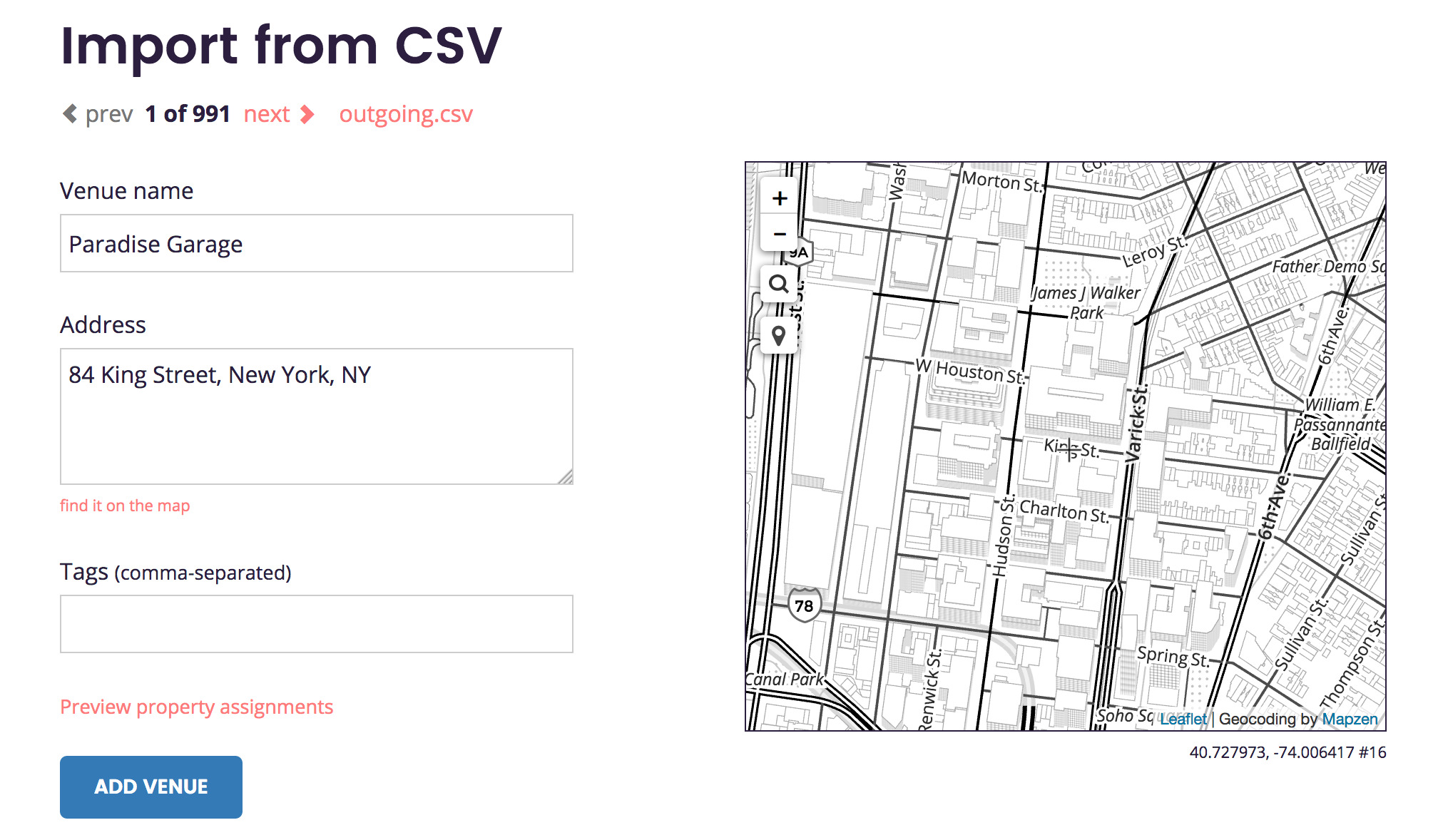
This row-by-row process allows us to make any necessary adjustments to the record before we import it into the Who’s On First dataset. In some cases, we may need to choose which address is the correct one.
We also want to avoid duplicating existing records, if possible.
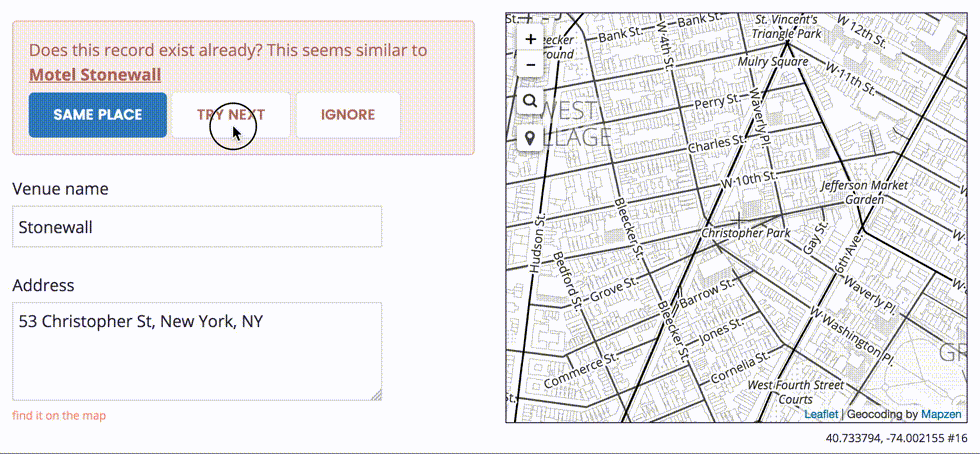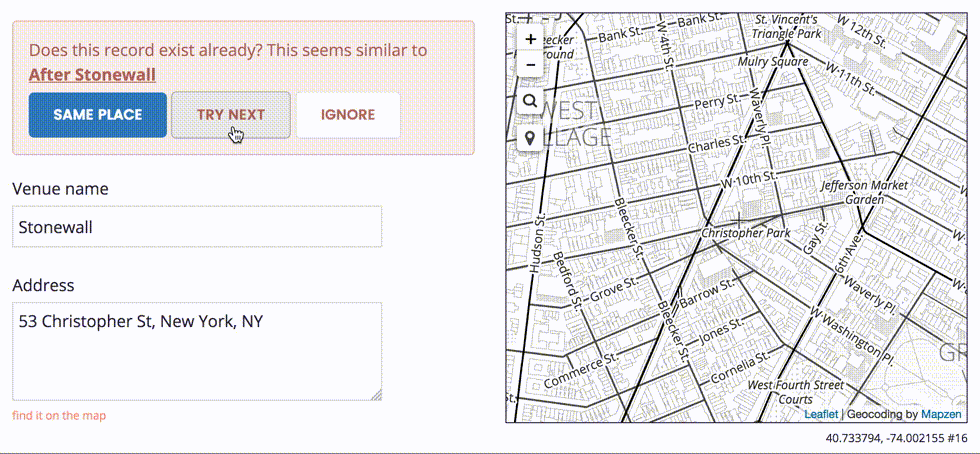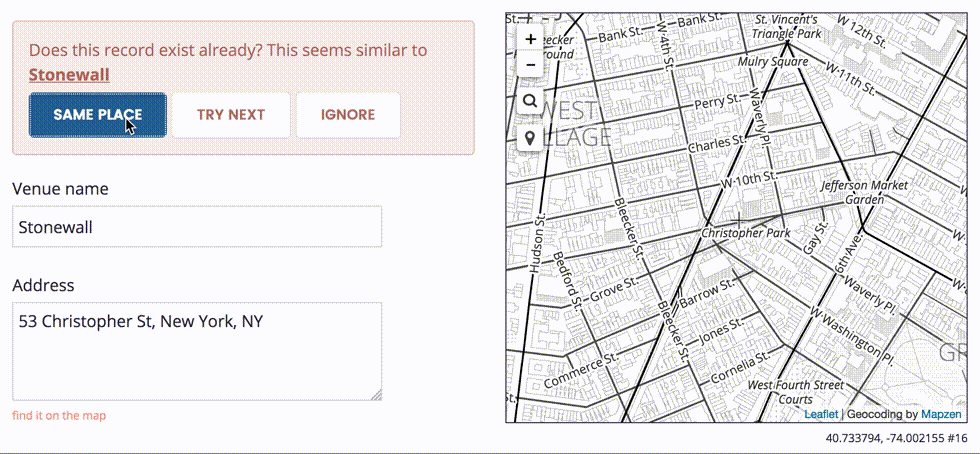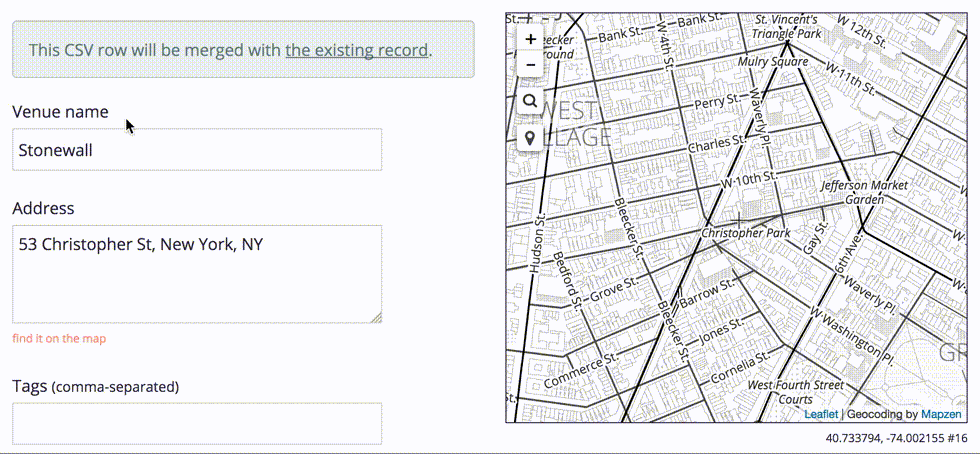
Once we complete the step-through import process, we can download a new CSV file modified to include a new wof_id column. This additional column allows us to round-trip our edits back into Who’s On First, effectively turning your spreadsheet editor into a new external interface to change properties en masse.
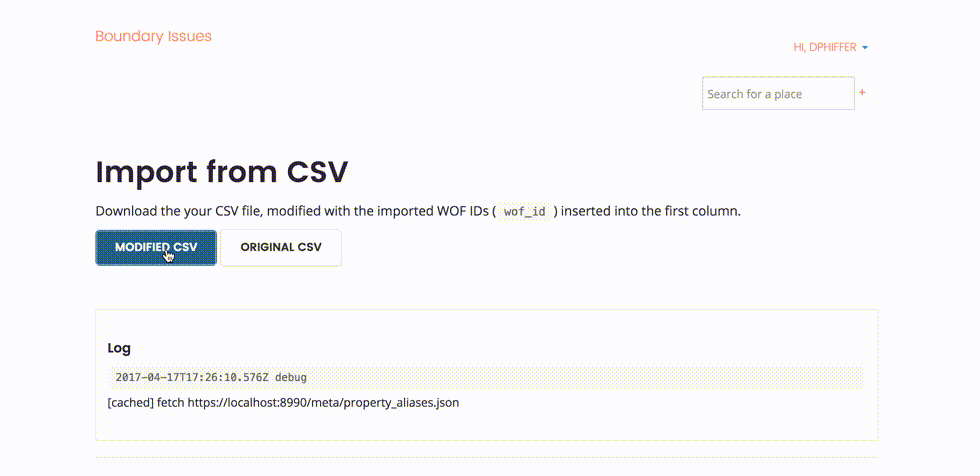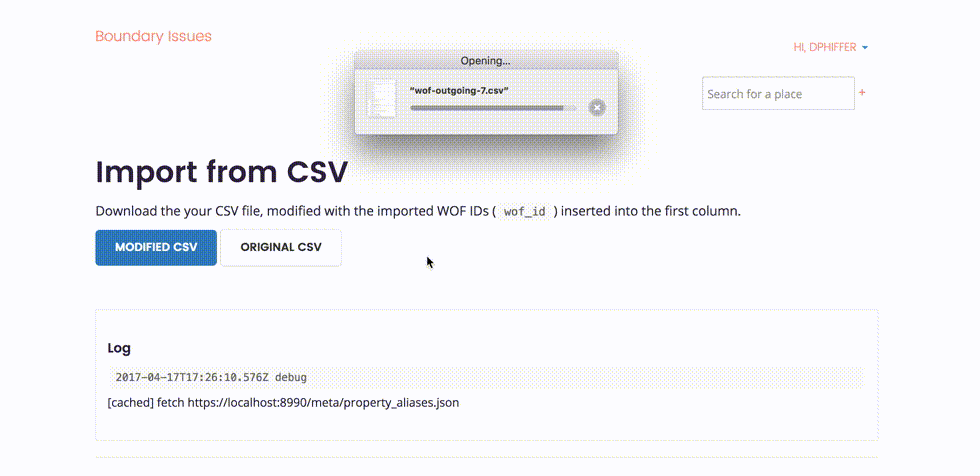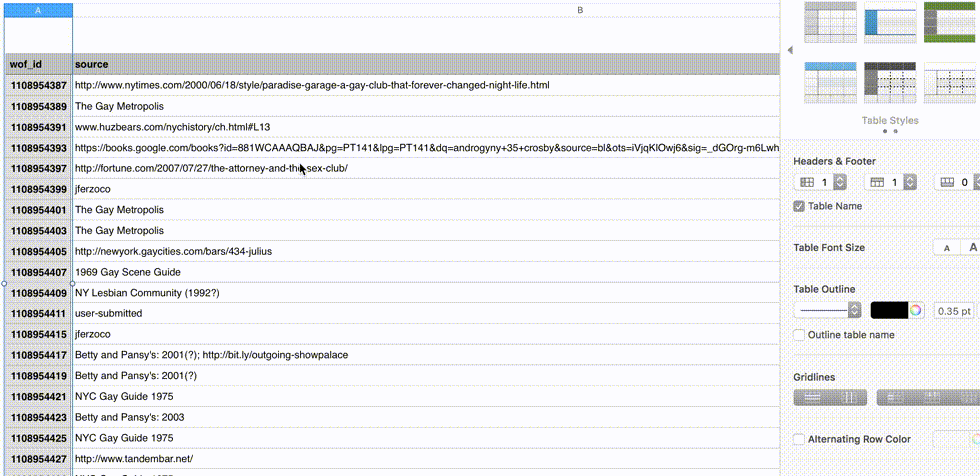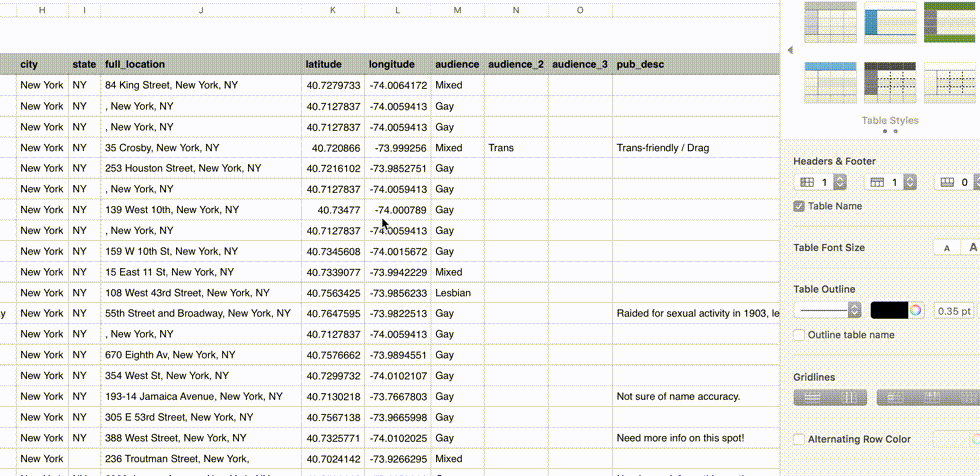
Working with real data has been extremely helpful for shaping the CSV step-through feature. Huge thanks to Jeff for sharing his research and for being so generous with the underlying dataset. The OUTgoing data is quirky and opinionated, and was instrumental in identifying unexpected edge cases as I was writing the code.
We look forward to meeting your weird and wonderful CSVs!
Excuse me while I promote some things here
Plug #1: This blog post was adapted into a talk at csv,conf on May 3 in Portland, OR. Thanks for coming by! Here are the slides, and the slides + video if you missed it.
Plug #2: We are extending the deadline for our call for internship applications. Please apply if you found this discussion interesting, and want to help us improve how we we present Who’s On First to the world.

{kind=link}